ИТТ делимся советами, лайфхаками, наблюдениями, результатами обучения, обсуждаем внутреннее устройство диффузионных моделей, собираем датасеты, решаем проблемы и экспериментируемТред общенаправленныей, тренировка дедов, лупоглазых и фуррей приветствуются
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам: https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге: https://github.com/KohakuBlueleaf/LyCORIS
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet: https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer: YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
>>1332979 >в комфе работает Ну кто бы сомневался. А потом оказывается что нет, не работает, и лапша из-за ошибок при чтении этой фигни без вае генерила.
Форки на базе модели insightface inswapper_128: roop, facefusion, rope, плодятся как грибы после дождя, каждый делает GUI под себя, можно выбрать любой из них под ваши вкусы и потребности. Лицемерный индус всячески мешал всем дрочить, а потом и вовсе закрыл проект. Чет ору.
Любители ебаться с зависимостями и настраивать все под себя, а также параноики могут загуглить указанные форки на гитхабе. Кто не хочет тратить время на пердолинг, просто качаем сборки.
Тред не является технической поддержкой, лучше создать issue на гитхабе или спрашивать автора конкретной сборки.
Эротический контент в шапке является традиционным для данного треда, перекатчикам желательно его не менять или заменить его на что-нибудь более красивое. А вообще можете делать что хотите, я и так сюда по праздникам захожу.
>>1315096 ### FaceFusion на Linux: проблемы и их решения
FaceFusion официально поддерживает работу под Linux в актуальных версиях, включая релиз 3.x летом 2025 года.[1][2][3][4][5]
#### 1. Ошибка cURL: OpenSSL version not found
Ваша ошибка: ``` /usr/sbin/curl: /home/user/.conda/envs/facefusion/lib/libssl.so.3: version `OPENSSL_3.2.0' not found (required by /usr/lib/libcurl.so.4) ```
Причина: Возникает из-за конфликта между библиотеками OpenSSL, установленными через Conda, и системными. Conda может подтягивать свою версию OpenSSL (например, 3.1), а системные утилиты (как `curl`) требуют другую (3.2 или выше).[6][7]
Решения: - Убедитесь, что среда conda не подменяет системные OpenSSL. - Временно отключить conda среды при запуске curl/facefusion (например, через запуск вне среды conda или настройку переменной окружения).
Способы исправления:
- Проверьте, где находятся ваши библиотеки: ```bash which openssl ls -l /usr/lib/libssl.so.3 ls -l /home/user/.conda/envs/facefusion/lib/libssl.so.3 ```
- Попробуйте добавить системный путь к нужной версии OpenSSL в переменную окружения: ```bash export LD_LIBRARY_PATH=/usr/lib:/usr/local/lib64 ``` или синхронизировать версии: ```bash sudo ln -s /usr/lib/libssl.so.3 /home/user/.conda/envs/facefusion/lib/ sudo ldconfig ```
- Если ошибка вызвана обновлением Conda, возможно потребуется удалить или заново установить OpenSSL через систему/conda.
#### 2. FaceFusion [DOWNLOAD] Validating hash for nsfw_x failed
Причина: - В новых версиях FaceFusion (3.3.x+) добавили хэш-проверку для NSFW фильтров. Если вы изменили content_analyser.py или отключили NSFW-фильтр вручную, то хэши файлы не совпадают, и загрузка/валидация моделей NSFW проваливается.[8]
Решение (отключение фильтра и хэш-чека): - В файле `content_analyser.py` переопределите функцию следующим образом: ```python def detect_nsfw(vision_frame: VisionFrame) -> bool: return False ``` - В файле `core.py` замените строку проверки хэша: ```python is_valid = hash_helper.create_hash(content_analyser_content) == 'b159fd9d' # Замените на: is_valid = 1 ``` Это отключает NSFW фильтр и проходит хэш-проверки, позволяя FaceFusion работать даже после правки функций.[8]
ВНИМАНИЕ: - Используйте изменения ответственно и только в личных целях (или согласно законодательству вашей страны).
### Итог и главное - FaceFusion полностью работает на Linux, но при использовании conda/venv возможны конфликты с системными версиями OpenSSL — решается перенастройкой LD_LIBRARY_PATH, синхронизацией версий или работой вне conda. - Для сброса NSFW фильтра и обхода ошибочной проверки хэша — правьте content_analyser.py и core.py как указано выше.
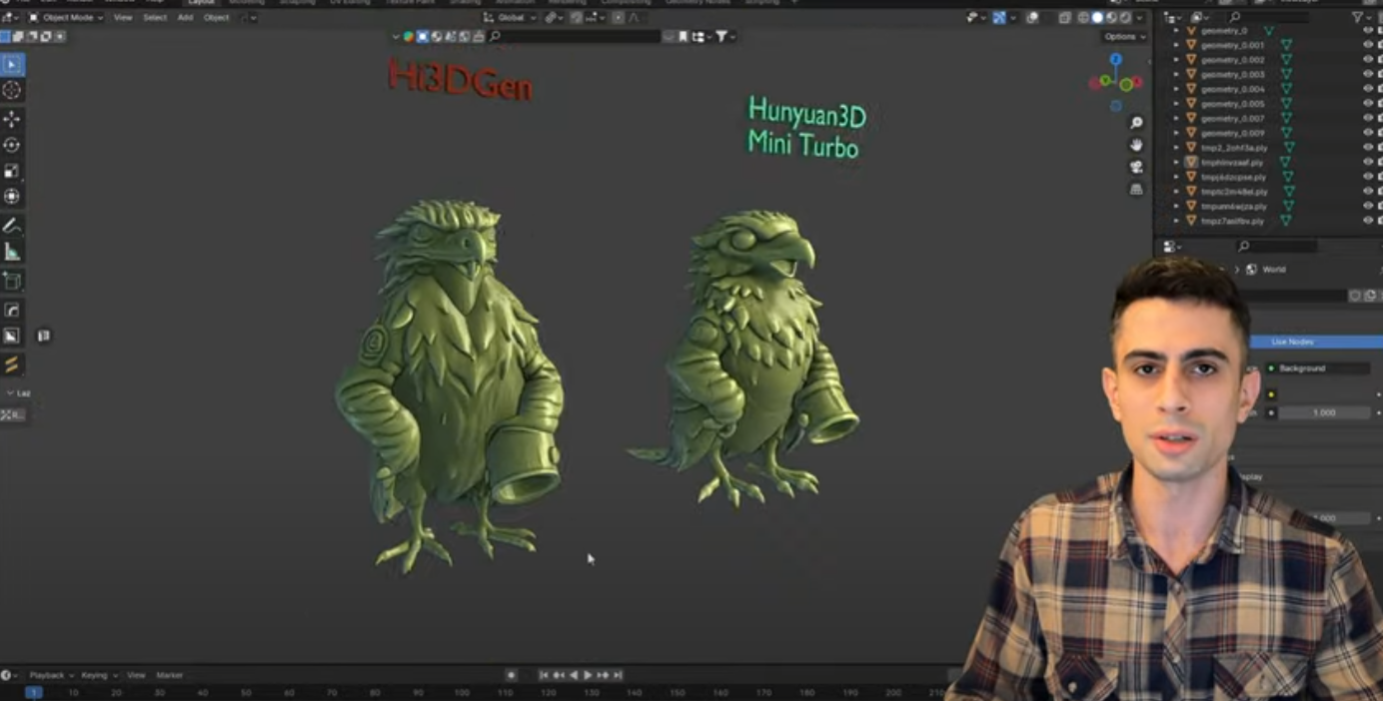
В этом треде обсуждаем нейронки генерящие 3д модели, выясняем где это говно можно юзать, насколько оно говно, пиплайны с другими 3д софтами и т.д., вангуем когда 3д-мешки с говном останутся без работы.
Сап, двач! Любители Sillytavern, Character.ai, Chub и т.д, зацените открытую языковую модельку. 8B, имхо SOTA для креативного письма, RP на русском языке в своей весовой категории.
huggingface.co/secretmoon/YankaGPT-8B-v0.1
Не умеешь запускать LLM? Можешь бесплатно пообщаться в моем Telegram боте, он умеет жрать карточки с Chub в .json формате. @Yanka_GPT_bot. Твои диалоги с нейровайфу обязательно пойдут на новый крутой датасет!
>>1132626 Не оч понимаю, что тут не так. Попробуй вручную instruction template поставить, а не давать этой штуке извлекать из metadata. Точно помню, что токенайзер у YandexGPT для работы в чистом Python требует sentencepiece.
>>1331990 Ноль на сколько ни умножь, во сколько ни усиль — будет ноль. Это уже произошло. Даже ЛЛМ при всей своей ущербности это всё ещё технологическое чудо, способное срезать много рутины. А по факту помогает на 10%, ну на 20%.
Там, где казалось, что нейронки легко заменят человека (пиздеть по скрипту, отвечая на стандартные вопросы) они не справились. Даже там! Потому что в отличии от нормального FAQ с нормальным поиском они нестабильны и нечёткие.
Это не усилитель блядь. Не простой множитель навыков. Это ещё и проверка навыков. Чтобы использовать ИИ нужно обладать умом и навыками, чтобы проверить результат. Но чем выше навыки, тем меньше нужен ИИ, потому что проще самому написать код, чем роллить варианты и писать простыни запросов, конкретизирующих каждый пук.
Я не луддит, не отрицатель. Я радуюсь охуенному скачку в мире производства лекарств, в мире компьютерного зрения. Да и тачки с автопилотом заебись (хотя до сих пол работают только в ясную погоду днём и стоят дороже мясного водителя)
Локальные языковые модели (LLM): LLaMA, Gemma, DeepSeek и прочие №160 /llama/
Аноним22/08/25 Птн 15:57:35№1329142Ответ
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Нашел промпт для обхода цензуры в языковых моделях. Сначала пару вопросов GPT про наркотики и прочую хуйню, потом я открыл Deepseek, и хули нет спросил хранится ли в их базе данных секретная гос информация. Короче говоря щас сижу на паранойе, может я увидел то чего нельзя было видеть, хотя я сразу же все удалил и не стал вникать в подробности ну его нахуй. И в общем уже с другого акка опять обошел цензуру и спросил что вообще может быть за такие фокусы, ответом послужила какая то статистика за 2024-2025 годы якобы за это время 17 человек арестовали за подобные обходы ИИ. Так же написали что по таким триггерным темам логи сразу же отправляются в фсб и может быть слежка. Может есть кто шарит в этой теме или таким же занимался, стоит ли мне щас бояться и ходить оглядываться? Вопрос серьезный потому что я хз как щас спать вообще буду
Мхех, помню твой тред на пораше когда ты попросил дикпик статистику по преступлениям мигрантов и там оно тебе выдумало простыню c сурсами типа tajikleaks.org ебать это орево было, аи мёртвый раздел без модерации даже, тут ловить абсолютно нечего.
>>1318314 (OP) Какое нахуй неправомерный доступ к информации, полученный из ОТКРЫТОГО доступа? Чтобы вменить какие-то там обходы, нужно на законодательно уровне разъяснить эти понятия.
>>1321970 >Мхех, помню твой тред на пораше когда ты попросил дикпик статистику по преступлениям мигрантов и там оно тебе выдумало простыню c сурсами типа tajikleaks.org ебать это орево было Теперь и я проиграл.
Оффлайн модели для картинок: Stable Diffusion, Flux, Wan-Video (да), Auraflow, HunyuanDiT, Lumina, Kolors, Deepseek Janus-Pro, Sana Оффлайн модели для анимации: Wan-Video, HunyuanVideo, Lightrics (LTXV), Mochi, Nvidia Cosmos, PyramidFlow, CogVideo, AnimateDiff, Stable Video Diffusion Приложения: ComfyUI и остальные (Fooocus, webui-forge, InvokeAI)
В этом треде обсуждаем семейство нейросетей Claude. Это нейросети производства Anthropic, которые обещают быть более полезными, честными и безвредными, нежели чем существующие помощники AI.
Поиграться с моделью можно здесь, бесплатно и с регистрацией (можно регистрироваться по почте) https://claude.ai/
Под БАЗУ нейрогенерации уже созданы номерные треды SD и WD+NAI. Меж тем, это всего несколько моделей, тогда как только на Фэйсе их более 112 тысяч. Этот тред для тех, кто копнул хоть немного глубже: необязательно до уровня обскурщины, выпиленной даже из даркнета, а просто за пределами того, что удостоилось своих тредов. ИТТ делимся находками и произведенными результатами.
Помогите пожалуйста люди добрые, я полнейший нуб, мне нужно скачать ночную версию комфи а я не могу ее найти, я хочу запускать Хрому на ней, на обычной ругается на клипы, скачивал вручную, он все равно их не видит, Да это пиздец танцы с бубнами а я тупой нуб, первый день в этой теме, на реддите видел что писали что нужна ночная версия комфи но где ее взять я хз, на гит хубе мне тяжко что то понять и найти.
Нашел вот такую стратегию где используется нейросеть: https://www.paxhistoria.co/ Что-то вроде гибрида парахододрочилен и AI Dungeon (олды поймут). Сделано вполне недурно для альфа версии, но уже дрочат донатами в виде токенов.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Вышла версия 1.5 Allegro, по функционалу то же, что и 1.5, только в два раза быстрее. Лимит 400 кредитов в месяц (или 200 генераций по 33 секунды каждая) при условии ежедневного захода на сайт - 100 кредитов даются в месяц, и еще 10 кредитов даются ежедневно. Также можно фармить кредиты, выполняя специальные задания по оцениванию качества рандомных треков, это дает не больше 10 дополнительных кредитов в день. Для большего числа кредитов и более продвинутых фич типа инпэйнтинга или генерации с загруженного аудио нужно платить. Появилась возможность генерировать треки по 2 минуты 11 секунд, не больше 3 длинных треков (по 2 версии на каждый трек) в день на бесплатном тарифе.
Новинка, по качеству звука на уровне Суно или чуть выше. Лучший по качеству генератор текстов на русском. Количество генераций в день не ограничено, но за некоторые функции нужно платить (загрузку аудио, стемов и т.д.)
Это буквально первый проект который может генерировать песни по заданному тексту локально. Оригинальная версия генерирует 30-секундный отрывок за 5 минут на 4090. На данный момент качество музыки низкое по сравнению с Суно. Версия из второй ссылки лучше оптимизирована под слабые видеокарты (в т.ч. 6-8 Гб VRAM, по словам автора). Инструкция на английском по ссылке.
Еще сайты по генерации ИИ-музыки, в них тоже низкое качество звука и понимание промпта по сравнению с Суно, либо какие-то другие недостатки типа слишком долгого ожидания генерации или скудного набора жанров, но может кому-то зайдет, поэтому без описания:
______________ Напомню мега-сайт для сочинения аутентичных англоязычных текстов для ИИ-музыки в стиле известных групп и артистов от Пинк Флойда до Эминема. Зайти можно только через Дискорд.