Литература: - Томас Кайт. Oracle для профессионалов - https://postgrespro.ru/education/books/dbtech - Алан Бьюли. Изучаем SQL. - про MySQL - К. Дж. Дейт. Введение в системы баз данных
Q: Вопросы с лабами и задачками A: Задавай, ответят, но могут и обоссать.
Здесь мы: - Разбираемся, почему PostgreSQL - не Oracle - Пытаемся понять, зачем нужен Тырпрайс, если есть бесплатный опенсурс - Обсуждаем, какие новые тенденции хранения данных появляются в современном цифровом обеществе - Решаем всем тредом лабы для заплутавших студентов и задачки с sql-ex для тех, у кого завтра ПЕРВОЕ собеседование - Анализируем, как работает поиск вконтакте - И просто хорошо проводим время, обсирая чужой код, не раскрывая, как писать правильно.
>>3122886 (OP) Какие варианты для вката есть, если ты хорошо знаешь SQL ( диалекты Postgre/Oracle и их процедурные расширения по типу PL/SQL)? Я редко вижу вакансии database developer'ов, в основном знание SQL это дополнение к какому-либо языку программирования. Писали, что можно с PL/SQL в банк пойти, но не по наслышке знаю, что сейчас тенденция у банков переходить на Postgre. Понятно, что процесс перехода не быстрый, но один хуй технология устаревающая, а хочется не остаться с голой жопой. Какие варианты сейчас вообще есть? Хотелось бы, чтобы сфера была не хайповая (особенно в части вкатунов) и не умирающая.
>>3124245 Попробуй Алана Бьюли "Изучаем SQL", там оч подробно расписана как теория бд, так и работа со всякими SQL-операторами. Пик скорее просто конспект документации постгре с примерами, лучше с более общего чего-то начать и потом переходить к этому
Делаю тестовые задания и нужно покрыть бд тестами. нужно несколько простых Тестов и несколько посложнее, например проверить связанность объектов в разных таблицах без ключей. Есть годные ресурсы поэтому вопросу? Или может быть гит какой-нибудь? хз даже че гуглить
Короче делаю магазин, в котором пользователь сможет сам создавать товары и дополнительные свойства товаров (например цвет, размер и т.д.). Естественно это все нужно фильтровать в поиске.
Посоветуйте, как лучше реализовать хранение этих свойств товара. Т.е. я создаю имя свойства, slug для поиска и значение. Значение может быть только одного типа. Как решение нагуглил, хранить тип в одном поле, а значение текстом в другом либо использовать json или EAV. EAV слишком сложно и много усилий требуется для выборок потом через ОРМ. Насчет первых двух пока сомнения в плане производительности. Использую postgres если что.
>>3125147 1) Ты никуда не денешься от дилемы json vs eav. C json соснешь когда кабаныч будет от тебя требовать аналитику. Например захочет узнать какого цвета платья в этом сезоне лучше продавались. Не то чтобы невозможно, будешь костыли городить. 2) Когда ты проектируешь ключевые фичи софта, позиция "слишком сложно, давайте сделаем проще" - глупая. Сложное не может быть простым .
>>3125147 >EAV EAV не нужен. Тебе нужна структура: товар, шаблон товара, свойства шаблона, значения конкретных свойств для конкретного товара. Пример. Шаблон: телевизор. Свойства шаблона: тип матрицы, диагональ итд. Товар: название: LG OLED65C3RLA, шаблон: телевизор. Значения свойств товара: тип матрицы: OLED, диагональ: 65 " итд.
>>3125449 Непонятно то ты предложил если не EAV. У тебя под каждый тип шаблона что ли таблица будет отдельная со своими столбцами для свойств товара или у тебя будет огромная таблица с сотнями столбцов под все свойства?
EAV как раз реляционная модель, чтобы не создавать таблицу для всех свойств всех товаров и еще иметь возможность динамически свойства добавлять.
>>3125147 Когда я делал похожую штуку, я сделал очень просто: сделал дополнительную таблицу и ебнул туда 10 колонок интов, 10 строк, 10 датавремя и так далее. У нас не магазин, у нас документооборот типа джиры, и пользователи могут добавлять кастомные поля к карточкам, в зависимости от типа. Для магаза я бы сделал похоже, взял бы таблицу Metadata (ProductId,TypeId,IntValue,StringValue...) и складывал бы туда эти кастомные свойства. Запросы получаются тривиальные: AND EXISTS(SELECT 1 FROM Metadata WHERE ProductId=p.Id AND TypeId=10 AND IntValue=55) чтобы показать все телевизоры с диагональю 55. Иными словами, классический EAV.
>>3125449 Нужно динамическое создание свойств. Шаблон не пойдет. >>3125246 Вот я и думаю сижу. >>3125650 Как-то не очень эффективно, плюс искусственное ограничение на количество свойств. Я не могу сказать заранее сколько свойств понадобится какому-нибудь клиенту.
>>3125715 Пчел... https://en.wikipedia.org/wiki/Relation_(database) Relation это "отношение" данных в кортеже (row) к атрибутам (column) в таблице. >'ID' from the domain of integers, and 'Name' and 'Address' from the domain of strings >A predicate for this relation, using the attribute names to denote free variables, might be "Employee number ID is known as Name and lives at Address".
А в EAV все колонки таблицы сведены в одну. В базе литератруно только одна таблица с тремя колонками: Entity (id), Attribute (column name), Value (value).
А схема, которую ты нарисовал, сохраняет семантику. Именно поэтому она никакой не EAV, по ней вполне можно формировать вменяемые предикаты, в отличие от EAV'а, где у тебя и "шаблон" и "свойства" и "значения" в одной таблице находятся.
>>3126086 >В википедии статьи пишут кукаретики, там много хуйни. Ты типа новую реляционную теорию разработал или че? Или старую опроверг? Когда уже весна закончится, столько шизиков и ебанутых давно не видел.
>Тебе анон нарисовал реальную рабочую схему. Это блядь моя схема. Ясен хуй она рабочая, она прямой сейчас в нескольких компаниях работает.
Если бы ты, хуйло слепошарое, читал тред, то увидел бы что речь шла о том что анон не понимает что такое EAV. И в чем разница между "реляционной моделью" и "EAV моделью". А чтобы это понять надо для начала знать что вообще такое "реляционная модель". И по каким "кукаретическим" принципам работает база данных, в которой тебя, обезьяну тупорылую, научили бездумно создавать таблички.
>>3125715 >>3125742 А, я неправильно тебя понял. Такую штуку я сам сделал изначально, с разными полями для разных типов. Не знаю как выбрать товары, у которых цвет красный и размер равен 42, например. Естественно, одним запросом нужно.
>>3126557 В чем проблема? SELECT product_id FROM values WHERE property_id=10 AND int_value=20 подразумевая, что 10 - это свойство "цвет", а 20 - "красный". Берутся эти значения из селектов на формочке, когда пользователь заполняет форму поиска.
>>3126574 Ты тупанул в тот момент, когда вместо изучения литературы из шапки запустил жпткал. И вывалил тебе жпткал лютейшей хуйни. А если свойств будет пять, а если десять? Я про перфоманс этого дерьма даже и не говорю, просто про читаемость.
Вот так это делается https://dbfiddle.uk/1MYQQ2Ek На индексы похуй, я хотел семантику показать. Таблицы связаны между собой в виде ромба, и начать запрос можно с любого угла, с того который выборку максимально уменьшит. А если в таблицу со значениями еще и колонку с идентификаторами шаблонов добавить, то можно будет совсем интересную аналитику делать.
Короче учи SQL, чтобы не быть баттхертом. А жптговно тебе в лучшем случае переврет какое-то рандомное говно из интернета, а в худшем просто насрет бредом.
>>3126740 Как удобно, когда у тебя все значения строкового типа. Изначально вопрос был, про то как хранить и выбирать значения разных типов. Нужны фильтры размер от 10 до 50, например. Булевы еще.
>>3126874 Лол. А зачем тебе "разные" типы? Ну вот зачем тебе INT, например? Значения это в принципе не INT. Они могут быть отрицательными? Их можно складывать/делить? Зачастую еще и единицы измерения надо как-то прикручивать.
Нахера весь этот геморрой, если все эти значения в конечном счете показываются на сайте в виде СТРОКИ? У тебя и так будет механизм, превращающий твои "булевы" значения в читабельные "Да/Нет" или "Есть/Нет".
>>3126874 Забыл про значения "между", "больше/меньше" и прочее. Вот так это можно сделать прямо в SQL https://dbfiddle.uk/xRkE5wzL Хотя обычно это делают в приложении, когда запрос составляют. Ты буквально можешь выбрать формат сравнения в зависимости от параметра.
>>3127484 >ведь не существует же таких джуниорских позиций Вы заебали уже джуниорскими позициями. Они чё блять какие-то особенные? Там меньше работают, меньше требуют или чо. Они абсолютно идентичные по всему, там просто добавили слово junior в заголовке и всё. Это обычный сраный кликбейт, чтобы больше людей откликнулось.
>>3127547 Там меньше платят. Если сразу платить много человек выгорит даже не поработав в сфере ИТ. А так у чела будет цель к чему стремится и въебывать.
>>3127572 >Там меньше платят Это вообще ничё не значит. Бывает что на вакансию с 30к зп претендует 200 человек. И наоборот, на зарплату 300к претендуют 2 человека. У нас полно долбоёбов с низкой самооценкой, готовых работать "за еду", "за хоть какие-то копейки", в надежде что набьют опыт и уйдут в другое место. Готовы унижаться, лизать пятки. Хоть там будут платить 10к в месяц, всё равно туда припрёться стадо баранов и попросит их нанять. Низкая зарплата никого не отпугивает. Даже если там будут плётками пиздить, водить в кандалах, он всё равно скажет, ну как же! Это же опыт!
>>3127572 Ты пиздец как недооцениваешь то, на что люди идут РАДИ ОПЫТА. Они готовы быть терпилами год-два-три, терпеть всю хуйню, низкую зп, микроменеджмент, легаси код, хуёвое отношение, неинтересные задачи, переработки, работу в праздники, лишь бы получить строчку в резюме.
>>3127484 >>3127547 >>3127572 Не существует джуниорских СПЕЦИАЛИЗИРОВАННЫХ позиций. Джуниор нужен когда "немного того немного этого", "ну хоть как-то", "че-то надо". Денег нет, но хоть че-то надо. Вот это работа для джуна.
А на специализированную должность нужен, внезапно, СПЕЦИАЛИСТ. И вопрос "как мне вкатиться" нужно переделать в вопрос "как мне стать специалистом". И сразу все понятно: хуй пойми как, тяжело, долго, без гарантий. И сразу всякие тупорылые катящиеся клоуны покатятся в другую сторону.
>>3127629 Двачую. Он пока никто, зеро. Логично, что вначале все будут отказывать. Вырастет как специалист, тогда его работодатели сами начнут приглашать на работу. Устройство на работу вначале это по сути брутфорс. После того как откажут первые 10-20-30 раз, где-то на 15-м или каком-нибудь собеседовании он устроится, если не сдастся и не съебёт в другую отрасль.
>>3127632 Я не об этом. Я о том что варианты: >Стать специалистом (Яндекс Наебтикум) -> Устроиться на спец вакансию И >Притвориться специалистом (наебать) -> Устроиться на спец вакансию Это по умолчанию попытки что-то скроить и кого-то наебать (возможно самого себя).
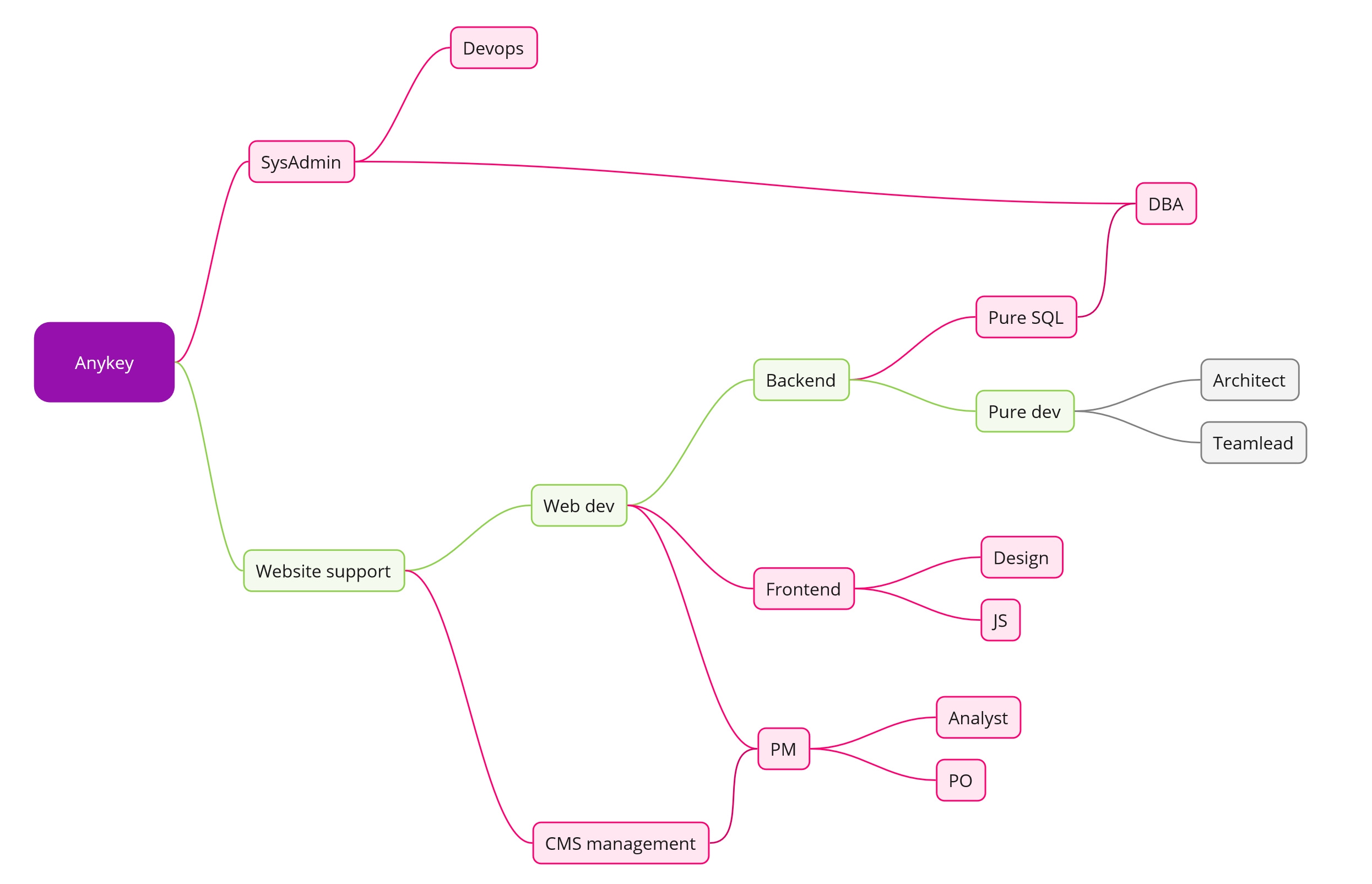
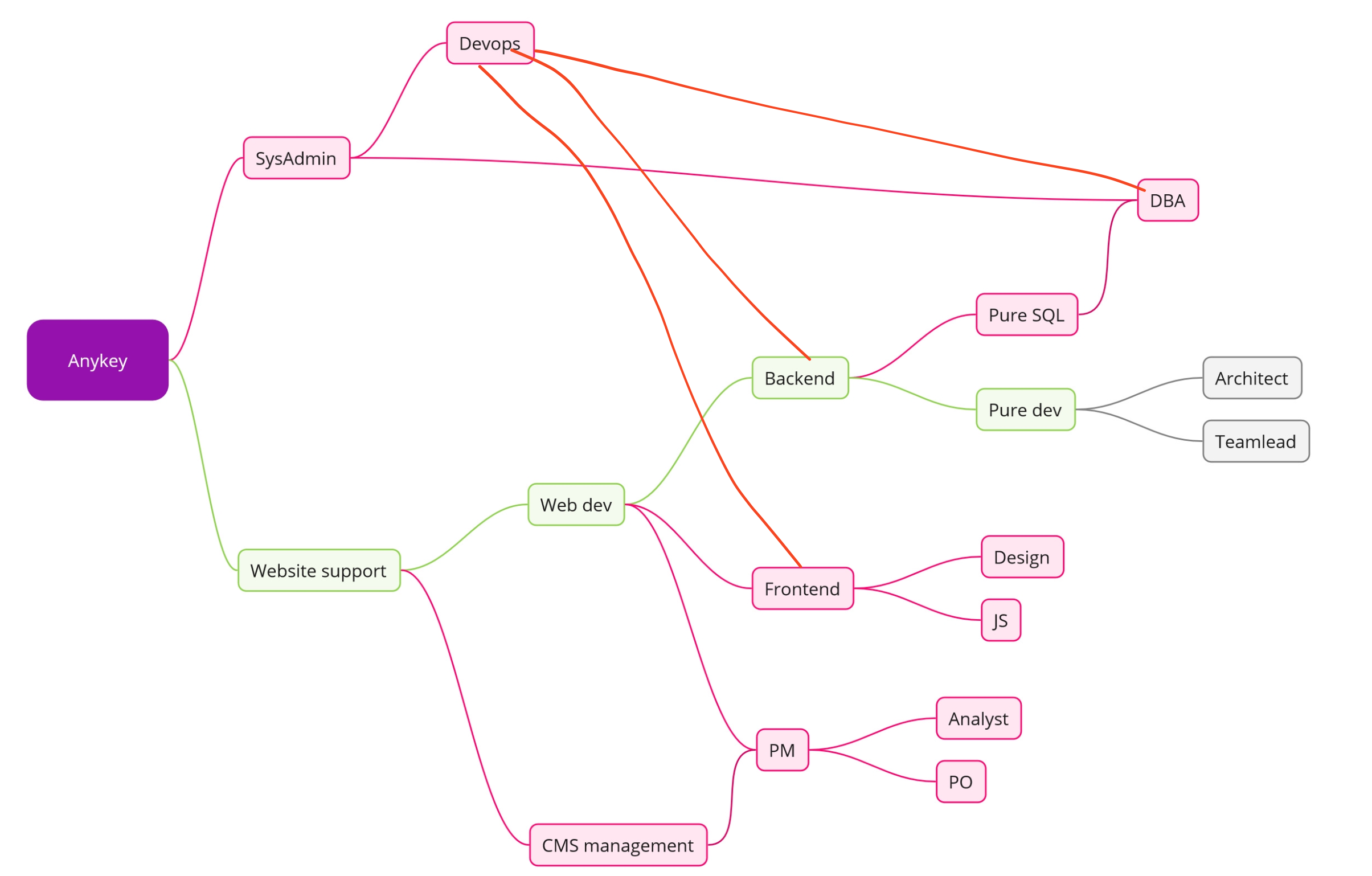
Пикрелейтед примерный маршрут "вката" моего и людей, которые были вокруг меня. Понятно что границы условные. Но. Это я решил что красноглазая хуйня не для меня. Это я решил что sql процедуры это не то что я хочу видеть восемь часов в сутки. Это я решил что рот ебал пиксель перфект адаптивной верстки и вешать поведение на кнопочки.
И мне блядь ни на секунду в голову не приходило спрашивать в интернете как вкатиться на узкоспециализированный стек. Потому что ответ очевиден: ты открываешь резюме и устраиваешься на подходящую тебе вакансию, туда где есть интересующая тебя хуйня. Через несколько месяцев, даже просто от поглядывания со стороны и разговоров в курилке, у тебя инфа по этому стеку из носа течь будет.
А если ты предыдущий абзац осуществить не в состоянии, то охлади траханье. И поделай че попроще. Можешь конечно и "побрутфорсить" головой об стену и попытаться получить все и сразу. Если станешь тем самым одним из тысячи, то мое почтение. Только есть подозрение что людям, у которых башка на столько хорошо варит, советы долбоебов с двачей не очень нужны.
>>3127547 Суть вопроса была не в поиске джуниорских вакансий, а в том, что такие вакансии изначально предполагают наличие аналогичного опыта, которому непонятно откуда взяться, поскольку, опять же, не существует начальных позиций конкретно на эти спецухи. И тут возникает вопрос: если не существует начальных позиций на эти вакансии, то откуда берутся специалисты, которые на это откликаются и находят работу? Откуда они берутся?
>>3127792 >если не существует начальных позиций на эти вакансии, то откуда берутся специалисты, которые на это откликаются и находят работу? Какая разница? Работодатель описывает ИДЕАЛЬНОГО КАНДИДАТА. Если баба на сайте знакомств пишет "хочу мужика красивого, с зарплатой от 300к", откуда возьмутся красивые мужики с такой зп? То есть, работодатель может хотеть чего угодно. Вопрос в том, если придут два кандидата например и они подходят только на 70%, но того нет и сего нет. Что будет делать работодатель? Он может либо ждать ещё месяц-другой-третий, либо он будет мириться с отсутствием чего-то.
>>3127917 Ну вот я читаю ОП, а там написано: >Q: Что лучше, SQL или NoSQL? >A: SQL. Вот я и спрашиваю, чем? Оно же там не просто так написано, правильно?
>>3127998 >Вот я и спрашиваю, чем? Оно же там не просто так написано, правильно? Холиварный вопрос, нельзя так сравнивать. Разных реализаций NoSQL с десяток и все они друг от друга отличаются. Если ты имеешь ввиду MongoDB, так и говори. Если CouchDB - это другой разговор. А если DynamoDB - то это третий. В одной ситуации одно лучше, а в другой ситуации другое. NoSQL практически не обладает развитым языком запросов (кроме MongoDB, у монги есть aggregation pipeline, у CouchDB mapreduce). В SQL ты не ограничен в запросах, можно хоть 5-ти этажные строить.
>>3128022 вот тут шмонга явно получше будет >>3125147 >Короче делаю магазин, в котором пользователь сможет сам создавать товары и дополнительные свойства товаров (например цвет, размер и т.д.). Естественно это все нужно фильтровать в поиске. но мы же не хотим простых решений. давайте лучше будем ебаться с EAV
>>3129022 Через неделю пользователь просит аналитику по продажам дилдаков красного цвета в регионе саратов и твоя монга обмякает. SQL тем и хорош, что можно писать любые запросы и крутить данные, как хочешь.
>>3129199 Вот тебе типичная задача из этой области. У некоторых товаров недозаполнили свойства. У некоторых телеков разъемы не прописали, у смартфонов объем памяти. Как найти все недозаполненное и оценить фронт работ для описателей, в твоей OLAP дрисне?
>>3129205 Схема примерная. Офк набор знаний у всех разный и требования тоже. Речь была о том что "вкат" в этой схеме происходит слева направо, в течении нескольких лет. А не в середину за три месяца, потому что где-то че-то прочитал.
>>3129217 >один SQL запрос >но мы же не хотим простых решений. давайте лучше будем ебаться с EAV >простое NoSql решение >пик с десятком говносервисов и стрелочек Это настолько хуево, что я даже не буду предъявлять за отсутствие в посте конкретного решения. Так говно себе по губам размазывать это надо уметь.
>>3129222 >один SQL запрос хахаха. ты рили веришь, что у бизнеса будет один запрос за все время? ну если твой манямирок реально такой, то проще простого >>3129203 >У некоторых товаров недозаполнили свойства. У некоторых телеков разъемы не прописали, у смартфонов объем памяти. Как найти все недозаполненное и оценить фронт работ для описателей, в твоей OLAP дрисне? Шаг 1: Получение списка всех свойств Шаг 2: Поиск товаров без всех свойств Шаг 3: Вывод результатов ПРОФИТ!
задаса изи. вообще при хорошем знании синтаксиса запрос пишется за 15 минут. при плохом за 30, чатжпт поможет если что. не вижу проблем
>простое NoSql решение Самое что ни есть простое. Создал коллекцию, дал креды беку — все.
>пик с десятком говносервисов и стрелочек А что нам не нравится? то есть делать какой-то анализ на продовой базе магазина норм, а пик не норм? повторюсь, если приходит бизнес и говорит: нам нужна онолитега на oltp — они идут нахуй
>>3129247 >хахаха. ты рили веришь, что у бизнеса будет один запрос за все время? Я про то что эта задача решается в ОДИН SQl запрос, алеша.
>ШагШагШаг И? Кто эти шаги будет делать? Где будут храниться результаты шагов? Как пользоваться итоговым результатом?
>Получение списка всех свойств Ты забыл слово "необходимых". Как ты будешь этот список "получать"?
>Поиск товаров без всех свойств Ошибка. У НЕКОТОРЫХ товаров нет НЕКОТОРЫХ свойств. У товара А нет свойств 2 и 3, у товара Б 1 и 3, у товара В только 3. Свойства 3 вообще нет в датасете, смекаешь?
>задаса изи. вообще при хорошем знании синтаксиса запрос пишется за 15 минут. при плохом за 30, чатжпт поможет если что. не вижу проблем А я не вижу запросов. Где запросы, билли?
>а пик не норм? То что на пике это не норма. Это маняфантазия для долбоебов.
>>3129256 >Я про то что эта задача решается в ОДИН SQl запрос, алеша. Петя, это ОДИН запрос в монге. Я помню банке работал, так там отчет формировался тоже за ОДИН SQl запрос. Правда в нем было около 1800 строк, но запрос был ОДИН >И? Кто эти шаги будет делать? кому надо тот и будет делать
>Где будут храниться результаты шагов? Как пользоваться итоговым результатом? на сервере естессно. по ccш подключаешься и смотришь в консольке. причем пот рутом. нужно только onoliteka.rar расспаковать че неудобно? ну а хуйли ты хотел? какие требования — такой и результат
>Ты забыл слово "необходимых". Как ты будешь этот список "получать"? охуеть какая сложная задача! в пострес же нельзя узнать имена всем существующих колонок в бд
>Ошибка. У НЕКОТОРЫХ товаров нет НЕКОТОРЫХ свойств. У товара А нет свойств 2 и 3, у товара Б 1 и 3, у товара В только 3. Свойства 3 вообще нет в датасете, смекаешь? Это ты только что узнал как документы в коллекциях хранятся?
>А я не вижу запросов. Где запросы, билли? >То что на пике это не норма. Это маняфантазия для долбоебов. Как и аналитика на проде. Поэтому в очередной раз для самых самых тупых поторяю — с такими запросами вы идете нахуй сделать аналитику на проде? а может сразу модели нейросетей крутить?
>>3129265 >это ОДИН запрос в монге Ну так где он? Пуки вижу, запроса не вижу.
>нужно только onoliteka.rar расспаковать А с SQL не нужно.
>Как ты будешь этот список "получать"? >пук Весомо. Аргументированно.
Дегенерат, ты так и будешь пердеть в тред? Ты либо пруфаешь конкретными запросами и результатами, что на монге-хуенге эту задачу сделать вообще возможно, либо сглатываешь. Все твои охуительные истории про какие-то выдуманные банки, про хуйню и малафью никому не интересны. Своим протыклассникам будешь эту лечку гнать. А тут без реального кода, ты так и останешься вечно обоссанным пиздливым nosql попущем.
>>3129272 Ну обосрался. Обосрался же? Обосрался. Нахуя дальше на себя то ссать? Ну так и скажи: не ебу я как это делается в монге, пизданул не подумав, проблематику не знаю, думал оно лучше, да походу нет. Почему каждый раз так: прибегает очередная nosql маня, ррякает и верещит как же все там заебись, а когда её просят решить малейшую прикладную задачу, мгновенно сливается.
Ну бквально же итт: >вот задача, вот так она решается на SQL >а на nosql все это легче и быстрее >покажи >пошел нахуй Стронгли пруфд ноускьюл супериорити. Не снимая штанов, как грится.
>>3129274 У меня вообще-то основная специальность MSSQL и Databricks. Но там где проще использовать NoSQL, я конечно использую MongoDB или Redis или еще что-нить. А иногда тупо parquet в s3 складываешь. А где надо реляционку, то могу и PostgreSQL или MySQL. Но MSSQL — это топ для меня конечно, но не для нищебродов. Только полные дауны используют один инструмент для всего как серебряную пулю. Поэтому если ты зациклился на сукили и не можешь такой запрос написать для монги — поздравляю, ты обосрался. Причем конкретно. Не нужно свою узколобость пытаться выдать за выдающие знания в БД. А если ты думаешь, то я по первому твоему кличу побегу писать тебе запросики — ты не просто даун, а полный даун. Поэтому еще раз — иди нахуй.
>>3129274 >прибегает очередная nosql маня, ррякает и верещит как же все там заебись, а когда её просят решить малейшую прикладную задачу, мгновенно сливается. Лох подорвался, с пеной у рта чёто там доказывает. Успокойте шизика, дайте ему таблетки. А то он горящим пердаком спалит всю хату.
>>3129172 >Через неделю пользователь просит аналитику по продажам дилдаков красного цвета в регионе саратов и твоя монга обмякает На ---> https://pastebin.com/GfWZ2HG5 а то у тебя пердачелло сгорит ещё больше. Это пример аналитики по продажам в монге.
>>3129289 >бесконечная стена write-only джейсона вместо 10 понятных строк на sql Все-таки использование джаваскрипта и производных приводит к органическим поражениям головного мозга. Что в коде, что в запросах.
>>3129277 >А если ты думаешь, то я по первому твоему кличу побегу писать тебе запросики Нахуя мне, ты напиши тому анону, которому ты влечивал какая монга в этих задачах охуенная. Я-то ему и "запросики" дал, и что таоке EAV объяснил. Потому что это легко и просто, дело десяти минут.
А ты бегаешь по треду с порванной жопой, хотя мог просто на чилле запостить "легкий и простой" запрос в монгу и закрыть вопрос. А ты чего только не высрал: и "я важный, хуй бумажный", и "мне вас жаль", и "я ничего никому не должен". Платина за платиной.
>>3129526 >аноны мне нужно хранить объекты без схемы данных, какое просто решение? > MongoDB или аналогичные >не подходит, вдруг попросят аналитику, а я в разработке не шарю, поэтому не могу продумать и создать оптимальное технологичное решение, зато я умею кодить на SQL и могу на проде крутить запросы Как называется эта болезнь?
>>3129542 КОго ты пытаешься наебать? >аноны мне нужно хранить объекты без схемы данных, какое просто решение? > MongoDB или аналогичные >А ОНО ПОДХОДИТ? Вот так можно? >АРРЯЯ иди нахуй
>>3129561 > напиши запрос на проде > иди на хуй. прод не для этого > ну а ты напиши Как называется эта болезнь?
>А ОНО ПОДХОДИТ? Вот так можно? А твоя реляционка может обрабатывать петабайты данных и крутить модели нейросетей? >>3129203 >Вот тебе типичная задача из этой области. Нужно показывать рекомендации которые посетитель магазина захочет купить. Причём модель должна дообучаться прямо в онлайне. Как это сделать в твоей дрисне?
>>3129599 Ты имеешь в виду и монгу и постгрес? Никто не мешает. Тем более сейчас, когда все в контейнерах. Тут все зависит от команды на самом деле. Если у тебя в команде только старперы, которые ничего нового не хотят, но зато умеют хорошо кодить на sql — они будут использовать только реляционку. Я когда н-цать лет назад пришел в одну контору, так у них все было в бд сделано. То есть схема была вебморда <-> бд. Вся бизнес-логика, весь бэк и все прочее было реализовано функциями и процедурами в СУБД. Если в команде есть архитектор или просто кто-то вменяемы с мозгами, то будут использовать подходящие технологии под каждый сервис
>>3129617 >Ну то есть тысяча человек? ну то есть топ-3 посещаемый сайт в мире >там за это время семь мажорных версий сменилось да хоть пятьсот. как это помогает решать бизнес задачу? у нас некоторые сервисы до сих пор на 9 крутятся
>>3129635 >ну то есть топ-3 посещаемый сайт в мире Он что ставит каждому посетителю mysql и заставляет этим говном пользоваться?
>да хоть пятьсот. как это помогает решать бизнес задачу? у нас некоторые сервисы до сих пор на 9 крутятся А у меня тетя тридцать лет все в блокнот ручкой пишет. Стабильная тема, переводите свои сервисы с постгри на блокноты?
>>3129638 как будто ты каждому пользователю ставишь свои мажорные версии
у тебя есть приложение банка, личный кабинет какой-нить, сайт жкх, да хоть игрулька какая-нить? зайди к ним на сайт или в приложении посмотри чейнджлог там нихуя не будет про мажорные версии бд — всем похуй
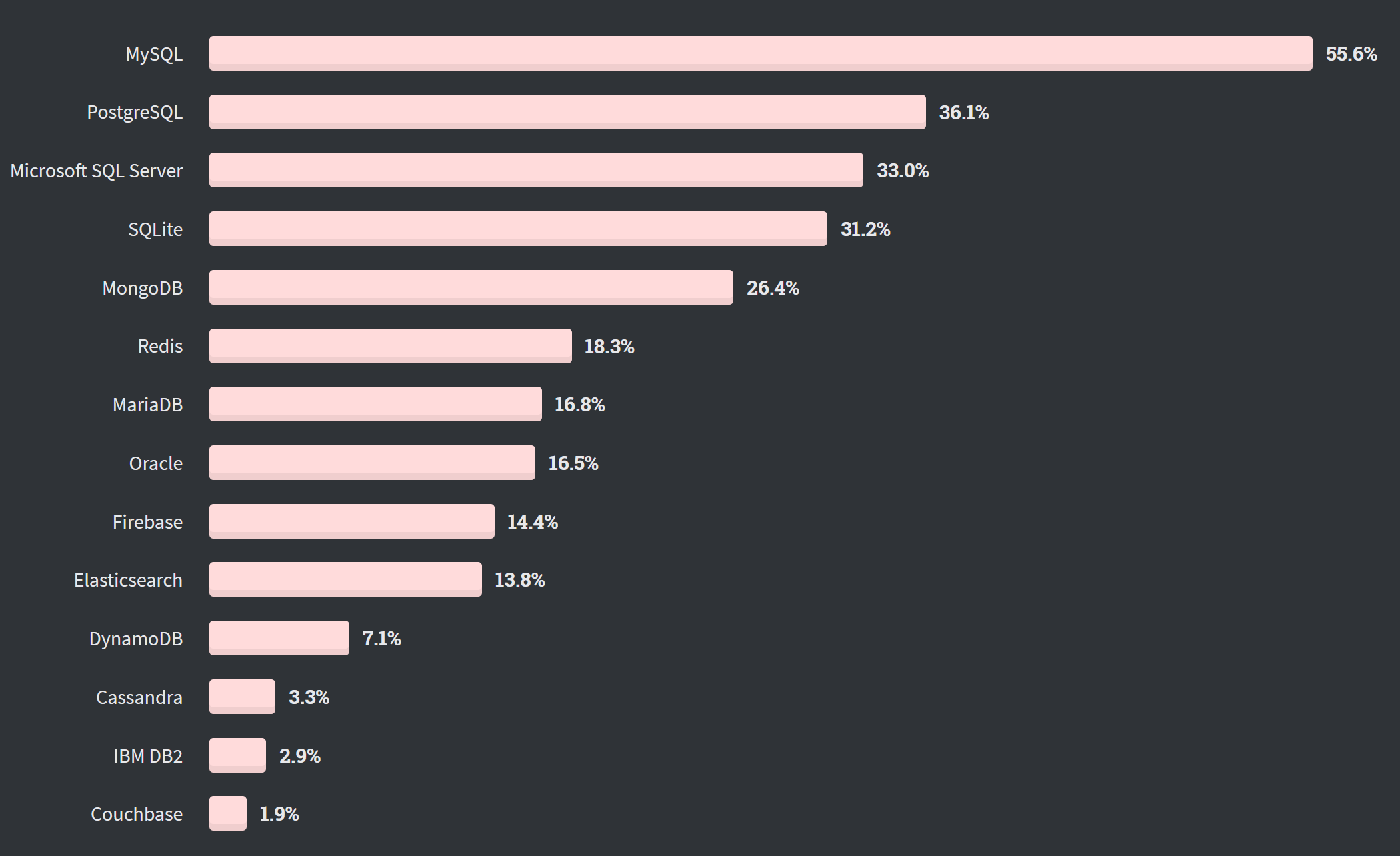
>>3129617 по популярности в интернете (посты, линкедин, вакансии etc) монго не далеко от постгрес, но даже в сумме они не дотягивают до мускуля >Ну то есть тысяча человек? если для тебя это важно, тогда используй монгу. там доля рынка гораздо больше, чем у постгрес
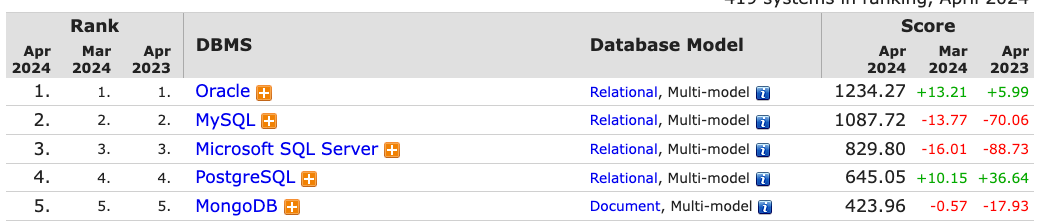
Мускуль и монга на дно, постгрес стабильно растет и пару лет назад занял первое место. Но самый цимес это разница между профессиональными голосами и голосами "вкатунов". Мускуль: вкатуны 58.40%/профи 45.68%, постгрес: вкатуны 25.54%/профи 46.48%, монга вкатуны 31.32%/профи 28.29% То есть приличная часть тренда сформирована людьми в технологиях нихуя не понимающих. И как только они матереют и видят реальную картину - они сразу откалываются.
Кстати, оракл по опросам реальных людей, всего 10%. Как так, гугл тренды жи?
>>3129929 >Вот вся статистика, которую нужно знать Не нужно. Все эти тренды это просто запросы в Google либо на stackoverflow. Поэтому неудивительно что по мускулю и постгрес так много вопросов и поэтому они в тренде. Все они являются вкатунами-нищебродами топящими за что-то бесплатное, в котором нихуя не разбираются. Поэтому приходится идти в Google либо на stackoverflow и спрашивать как это починять и таким образом генерировать тренд популярности. Как только они матереют, то сразу переходят на что-то серьезное типа скл сервер или оракла. И так как они уже профи, то вопросов задают мало и эти субд в тренды не попадают. К тому же появляются мозги и понимают, что нет универсального инструмента, поэтому где-то нужно использовать редис монгу кафку или даже хадуп с айсбергом. Никто с мозгами конечно не будет проводить онолитеку продаж на продовой бд. для этого есть двх и би инстументы типа табло. Или Яндекс.Метрику или Google Analytics где можно крутить вертеть смотреть воронку продаж
>>3129954 Может сначала читать, а потом пиздеть? Это результат опроса. survey в начале ссылки тебе ни о чем не говорит? Конкретных людей спрашивали: с чем вы работаете, с чем хотели бы работать.
Дальнейшие твои фантазии на тему просто бессмысленны, потому что ты еще на этапе предпосылки обосрался.
>>3129985 >Это результат опроса >результат опроса >опроса Опросил своих домочадцев и питомцев и по результатам этого опросы ты хуесос и говноед. Сорри, но это результаты опроса, а с ними не поспоришь.
Я вот работаю с MSSQL еще с тех пор, когда он не был MSSQL. С MongoDB лет десять. По паре лет с DinamoDB, Neo4j, InfluxDB. Но я не участвовал в этом опросе. Более того, в Сбербанке больше ораклистов, чем ты наберешь участников этого опроса со всего двача. >SQLite 3 место Ахахаха. Сериусли? А ты вообще прочитал что я написал? Вкатуны, нищеебы и мобильщики идут на stackoverflow спрашивать про свою попаболь и участвуют во всяких опросах, пока серьезные дяди разрабатывают решения на Oracle или MSSQL или даже DB2, это древнее дерьмо кажется в любом топ10 банке, которые сейчас двигают весь ИТ прогресс в рaщке. Эскуэлайт третье место. Бля, по моему это мем года
>>3130159 Пчел, ну и че ты высрал? Получилось три варианта: >рейтинг по гугл трендам >рейтинг по опросам программистов >мнение долбоеба с двача
Ты можешь сколько угодно угорать над опросами, но мнение анонимного хуесоса из двачерской клоаки стоит ниже любых гугл трендов. Да лучше базу по чиркашам на унитазе выбирать, чем слушать таких дегенератов, как ты.
>Ты можешь сколько угодно угорать над опросами На каурсере есть курс по дата кволити (советую пройти весь). Там как раз в первой части рассказывают как можно создавать предвзятые опросы, чтобы склонить опрашиваемых в нужную сторону. Например: Есть пять варианта: >мнение долбоебов которые гуглят "как найти красные дилдоки в монге" >мнение долбоебов со стековерфоу, которые из вима выйти не могут >мнение долбоебов с двача >мнение русских реперов >исследование Gartner реального рынка Ты за какой вариант?
>>3130159 >Я вот работаю с MSSQL еще с тех пор, когда он не был MSSQL. При Горбачеве что ли? Пиздишь. Первая версия Microsoft SQL Server 1.0 вышла в 1988 году и была совместимой с Sybase SQL Server, выпущенном годом ранее. Из местных кодеров самый старый Алексей Скуфьин, но даже ему в 1988 было всего всего 15 лет. Несовершеннолетних программистов в СССР на работу не брали.
>>3122972 NoSQL это высер маркетологов, который технический специалист употреблять не должен. Есть базы реляционные и нереляционные (документные, кэши "ключ-значение", графовые и т.д.). Программистишки поняли, что хранить комменты из гостевухи или чата в реляционной БД не самая лучшая идея и создали специальные базы вроде Mongo для этого. Но исторически реляционные базы появились позже нереляционных.
>>3130184 >вышла в 1988 году Ага вышла и сразу у всех в проде моментально оказалось причем даже даже в совке сразу видно что ты зеленый и даже не представляешь какой был интернет и как вообще работали в ИТ в нулевых, не говоря уже про модемный интернет и 90-ые короч, в нулевых в рф было полно Sybase кубернетисов не было. вообще виртуализации не было (на проде лет через 3-5 начали только внедрять) ты покупаешь дорогущий здоровеннный мейнфрейм от IBM и там у тебя будет либо Sybase либо db2 оракл юзали для второстепенных сервисов как сейчас постгрес
>>3130358 Обосрался прямо тебе в ротик мелкобуква, иди под струю мойся.
про память и запросы.
Аноним22/04/24 Пнд 09:57:30№3131356107
1) Я правильно понимаю, что mariadb не хранит все время в памяти базу данных? 2) Во время запроса всё таблицы базы данных загружаются в память? А не приведет ли это к нехватке памяти, если там огромные таблицы?
>>3131356 1) Очевидно нет, это же не redis и не memcached. 2) Загружается кеш, а не вся таблица. Размер query cache'а можно тонко регулировать в конфигах. Там много тонких настроек, от количества открытых файлов до innodb размера буфера, размер временных таблиц, размер логов и т.д.
Ну короче! Это всё регулируется через my.cnf в зависимости от ресурсов сервера, подгоняется под машину. Если ты слишком много чего-то укажешь, например 2 гб кеша а памяти только 1 гб, он либо уйдёт в swap, либо просто завершится и не будет работать. У innodb по-моему минималка 1 гб, но это не точно.
В чем особенность бд с низким потреблением буферного кэша? Уже пытался отвечать повышенное время отклика, тупеж параллельных вопросов да и хз что еще, тут ответ походу конкретный, но по ощущениям это морской бой догадками) Сорян если дублирую вопрос из одного треда в тред
>>3131753 Что за вопрос вообще такой уебанский? "бд с низким потреблением" Как БД блядь может быть с низким потреблением? У бд кеш либо есть, либо нет. А если есть, то его размер настраивается.
Особенность может быть у запросов, которые "потребляют мало кеша". Если у тебя десять записей в таблице, а в кеше только три, то это "низкое потребление" вызвано повторением одних и тех же запросов, между прочим для этого кеш и придуман.
А если у тебя миллиард записей и на каждый запрос выбирается случайная, то у тебя к нагрузке на диск и проц добавляется куча мусора в памяти и затраты на поиск в этой куче того, чего там нет.
>>3131856 >Не мой вопрос Да ладна. Бессмысленной хуйней он от этого быть не перестает. Так что либо спрашивал долбоеб, либо ты все переврал.
>Usage count кэша Опять какая-то хуйня. Нет такого термина "usage count". Что это блядь вообще должно означать? "Маленькое использование" кем? Тем кто сохраняет в кеш или тем кто достает? Ты понимаешь что это полностью противоположные ситуации?
Короче. "бд с низким потреблением", "Usage count" это тарабарщина. Если ты ДЕЙСТВИТЕЛЬНО на собесе это услышал, то тебя просто завалили хуйней, тебе туда не надо. А если ты сам это придумал, то новости печальные - ты профнепригоден, надо доучиваться.
>>3131886 Я прихожу на пересдачу уже третий раз и мне уже абсолютно поебать на формулировки этого препода. Изначально вопрос звучал так: "В некой бд usage count буферного кэша низкий, чем она отличается от бд с нормальным использованием буферного кэша?" На просьбу "повторите вопрос пожалуйста" ответ "а я забыл / а ты че не запомнил / надо было записывать". Уточняющие вопросы по вопросу идут туда же. Я никогда по-хорошему не работал с бд, usage count скорее всего указывает на число записей в кэш или к числу обращений к кэшу, я думаю, что скорее первое. Условие в том, что абстрактная бд довольно мало использует буферный кэш и в этих условиях мне нужно отвтетить, какое её главное свойство.
Мои догадки: 1. Данные почти всегда свежие 2. Возможно, кэшировали индексы и поэтому такой низкий usage count, что бы это не значило 3. Т.к. бд почти всегда обращается к тейблам и объектам, то несоответствие данных почти исключено 4. Какая-то неведомая "оптимизация" через три пизды, которая на внятный ответ не похожа
>>3131647 >2) Загружается кеш, а не вся таблица. Размер query cache'а можно тонко регулировать в конфигах.
Регулировать можно размер innodb page cache. А query cache - средство для оживления всяких drupal-ов. Отдельная и несколько штука. Насколько спорная, что в mysql 8 ее попытались выпилить, но в mariadb понимают что проекты бывают разные.
>>3131356 >А не приведет ли это к нехватке памяти, если там огромные таблицы?
инвалидация кеша ОС считается бесплатной. Настолько, что он есть, но в linux программы top не показывают этот кеш. А вот innodb page cache надо как-то подбирать экспериментально под свою нагрузку.
Куда в mariadb проебали настройку innodb_dedicated_server я понятия не имею, но ты ознакомься с документацией от Oracle Mysql
>>3131917 usage count ничего не означает. Есть термин "cache hit rate". Это отношение количества запросов удовлетворенных кешем к общему количеству.
Догадки твои - это не догадки, а такой же информационный шум, как и вопрос. С тем же успехом препод мог тебя спросить: хуй сосал, селедкой пахло? А потом сказать что: хуесосам незачет.
>>3131972 Не сходить ли тебе нахуй? Вместо того, чтобы хоть что-то предположить, рассматривая обе версии, что значит то или иное, ты просто срешь в переполненный унитаз, в результате чего твоя жопа и ноги в том же говне. Ты сюда пришел показать умственное превосходство или кому-то помочь, с тем же успехом ты можешь устроиться на линию доверия и вместо помощи человеку направлять его на суицид. Крч, ты не меньший долбоеб, чем я и препод, задающий мне эти вопросы.
>>3131753 > В чем особенность бд с низким потреблением буферного кэша? такого общепринятого термина нет. препод проверяет слушал ли ты его вообще - какую-то свою теорию создал
не совсем понятно это кеш записи или чтения. Допустим, ситуация с большим буфером записи и отложенной записью считается нетипичной для субд и ее исключаем.
Тогда остается чтение. Субд мало повторно читает. Теоретики делят СУБД по характеру использования на OLTP и OLAP. Описанное характерно для OLAP.
>>3131976 >Ты сюда пришел показать умственное превосходство или кому-то помочь, А я всегда и прихожу показать умственное превосходство. Просто в данной ситуации мне нравится удовольствие от того, что я понял пусть даже немного шизоидные мысли какого-то левого препода.
>>3131976 Пчел, еще раз. Препод тебя спрашивает: хуй сосал, селедкой пахло? КОгда ты пытаешься спрыгнуть, говорит: отвечать да или нет. А после твоего ответа: хуесосам незачет.
Твои действия? Ты идешь на двач спрашивать пахнет ли хуй селедкой?
>>3131980 Ни то, ни другое, я схожу с ума, я нихуя не понимаю и знаю, что у него есть какой-то конченый ответ, вокруг которого я ходил на протяжении пяти часов.
На вопрос "Как реализовать шардирование в базовом постгре" ответом было "partitioning". -_-
>>3132000 Шардирование делается на уровне кода, бд про это не знает. Партиции делаются внутри бд, код про это не знает. Твой препод долбоеб. Ты, случайно, не в епаме курсы проходишь?
>>3131980 Догадка, что мы много пишем мало читаем верна и от этого кэш маленький, следующий вопрос: "что нам говорит о бд то, что у нас много записи мало чтения?" Мысль, что это транзакционная бд, отклонена >.<
Нужно хранить большие объемы текста. Как лучше поступить: 1) Завести 2 таблицы: одна хранит только текст, другая информацию о тексте (название, размер и т.д.); 2) Хранить все в одной таблице.
>>3132602 Гугли у постгреса TOAST, эха хуйня делается автоматически на уровне СУБД. С какой целью ты хочешь делать на уровне приложения две таблицы - непонятно
>>3126740 >>3126874 Спасибо. Сделал CTE с желаемыми свойствами, к ним соединил свои свойства, сгруппировал по id продукта количество соединенных свойств и сделал HAVING количество свойств = количество фильтров, чтобы отобрать только те продукты, которые подходят по всем фильтрам. К этой уже таблице соединил продукты. Вроде заебись получилось.
Проблему с разными типами решил через jsonb поле, которое хранит примитивные типы. Со стороны ORM даже нет разницы json там или нет.
>>3133079 Тебе жи все показали >>3126943https://dbfiddle.uk/xRkE5wzL У тя подсчет количества пройденных фильтров бисплатный, пушо все равно дистинкт делается. И подсчет количества заданных фильтров бисплатный, пушо они в cte лежат, да и сколько там этих фильтров? Десять? Двадцать? А найденных товаров может быть десятки тысяч.
mysql: "Если текстовые файлы, которые нужно прочитать, находятся на сервере, то из соображений безопасности эти файлы должны либо размещаться в директории базы данных, либо быть доступными для чтения всем пользователям." Куда класть файл-то? Я даже не ебу куда mysql сохраняет файлы существующих БД. У меня нет никаких папок data.
>>3134993 > Куда класть файл-то? Для начала надо решить, насколько тебе важно держать в базе данных логику, а не собственно данные, и точно ли нельзя никак обойтись без этого. Обычно этим должно заниматься приложение, разве что у тебя какой-то особый кейс с аналитикой. > Я даже не ебу куда mysql сохраняет файлы существующих БД. Значит, надо узнать. Копай дальше документацию.
>>3135832 Имеется ввиду, что есть возможность заставить сервер читать файл и в этой ситуации загрузка еще более оптимизирована чем обычно, но тебе это не надо.
>>3138002 Браузер открывает 80-й порт, а постгрес у тебя на 5432. Проверь, запущена ли служба (в Windows Администрирование, Службы, в Linux - через systemctl). Проверь подключение через psql.
>>3138056 сделал ровно то же самое. за одним исключением: я все галочки за раз прожимал, в статье они по одному прожимались с дровами. установил один драйвер. малаца. запусти заново. выбери вторую. repeatx2 и базу пустую создал. после этого ругаться перестало на базу. так понял, на локальном компе есть и база, и сервер. только вот 1с сервер говорит: нету И в строке браузера тоже ввожу, ничего. Как серверу имя присвоить, чтобы введя в 1с его имя, или ip компа можно было базу подключать?
>>3138093 >>3138056 в целом, помогло, вы няши. но есть но. он ругается на кодировку при создании базы. нужно выбирать вместо РУССКИЙ ЯЗЫК (РРОССИЯ) просто РУССКИЙ ЯЗЫК.
но третья проблема: хасп ключ красный есть, а он не действует вроде как на сервер. сервер 1с локальный ругается, что ключа нет.
>>3129203 >Вот тебе типичная задача из этой области. >У некоторых товаров недозаполнили свойства. У некоторых телеков разъемы не прописали, у смартфонов объем памяти. Как найти все недозаполненное и оценить фронт работ для описателей, в твоей OLAP дрисне? Это не типичная задача, а какая-то двачерская маня хуета. Зачем это вообще нужно? Никто такой хуетой заниматься не будет Я вообще не понимаю о чем спор. Как будто некоторые люди где-то в начале 10-го годов остались и пилят какой-нибудь говно магазин на джумле с одной единственной базой, в которой и структура сайта хранится, и складской учёт ведётся, и продажи, и аналитика, и вообще все. У нас бизнес по оптовым продажам для b2b. Клиентов дай бог 3000 наберётся. Сайт работает на MongoDB, бэкенд сервисы на PostgreSQL, вся аналитика на Clickhouse.
>>3128106 >В SQL ты не ограничен в запросах, можно хоть 5-ти этажные строить А зачем? Есть какие-то бизнес-кейсы? На практике какие-то сложные и многосоставные запросы - это большая редкость. Тот же функционал монги и ORM для реляционок покрывает все потребности
>>3145479 >Есть какие-то бизнес-кейсы? Конечно, это в основном какие-то отчёты > Тот же функционал монги и ORM для реляционок покрывает все потребности Реляционка тебе все равно нужна будет, если у тебя будут транзакции, а у большинства бизнесов они есть. А дальше - значем тебе 2 базы данных, когда можно обойтись одной? Шах и мат.
>>3146196 маня задача с собеса? В реальной жизни такой хуйней никто не страдает.
>>3146175 Я только за последние полтора года пять проектов сменил. Бизнесу глубоко похуй у тебя портянка запрос или три строчки. Они хотят какую-то реальную задачу решить. Кто-то эти задачи решает портянками. А потом компания вырастает, и твои портянки начинают разъезжаться Вроде бы один и тот же отчёт, просто в разных разрезах, но показывает разные цифры Начинаешь проводить аудит, а там какой-то потяношиз нахуячил говна на 3к строк Привет
>>3146435 >маня задача Задача типичная. Классика жанра. Но это ведь не важно, правда? Потому что никто тебя, долбоеба, не спрашивал про степень маманястости задачи. Тебя спросили: можешь ли такое решить с помощью монги? Судя по пустопорожним кукарекам - не можешь.
Ну что, переходим к этапу "я никому не должен ничего решать, аррря"?
>>3146712 >>3146424 >А дальше - значем тебе 2 базы данных, когда можно обойтись одной? Шах и мат. Под себя серешь. принёс картинку с сайта крупного ритейла. У них там зоопарк sql+nosql решений. Кстати у меня вот тоже картинка есть. А дальше что? Под капотом сайта что работает? А запросы кто формирует? Вряд ли при каждом переходе страницы сидит кодер на sql и пишел свой скрипт
>Задача типичная. Нетипичная. Потому что тут вся сложность не в группировки и сортировке, а десятках джойнов, так как это все в разных таблицах храниться. С учётом того что в монге все это хранится в одной коллекции, запрос будет все две строчки: группировка и слайс
>Тебя спросили: можешь ли такое решить с помощью монги? Да, делал абсолютно аналогичную задачу. нужно было взять все продажи за час по разным категории и взять топ 10 в каждой. Делал все это на бэке через ORM
>>3146843 >запрос будет все две строчки: группировка и слайс Где запрос? Так-то пиздеть не мешки ворочать, я вот точно говорю что запрос будет в джва слова: слайсировка и хуйс. Верим?
>>3146843 >У них там зоопарк sql+nosql решений. Это не значит что оно там нужно. Вероятнее всего это какой-то такой же кодерок решил показать какой он умный и нахуярил всех технологий, которые на конференции услышал. Я так же видел зоопарк sql + nosql на одностраничном складе фотографий.
Я знаю как минимум три способа решения этой задачи на SQL. И все они за рамками автосгенеренных ОРМ крудов. Мне просто было интересно как эту простейшую задачу решит монгохуесос. Судя по всему никак не решит. Потому что он похоже и не монгохуесос вовсе, а просто шизик, который эту монгу в глаза не видел.
>>3146843 >Делал все это на бэке через ORM Это кинец Гонять сотни мегабайт по сети только чтобы протолкнуть своё хипстерковое решение - это просто вершина тупизма :(
>>3146888 Я даже не знаю почему компании ведутся на такую хуйню. Ведь можно нанять одного базиста + одного бекендера + одного фронтендера + одного мобильщика. ВСЁ! На хуя компания такой огромный и раздутый штат айтишников? Ведь одной базы и одного сайта достаточно для любых нужд.
>>3146894 >Гонять сотни мегабайт А почему не триллионы? Ты вообще знаешь как ORM работает?
>>3146892 >Я знаю как минимум три способа решения этой задачи на SQL Ты про манязадачу с двача или про типичную задачу реального бизнеса? Если про типично реальную задачу тогда берём вот такую функциональность >>3146712 Тебе нужно вывести на сайт топ пять товаров из трех самых популярых категорий этого пользователя или этого города, если незалогинен. База данных нормализована. Плюс нужно проверить остатки на складе. Ты же не будешь как долбоёб предлагать товар на главной странице которого уже нет. Цены динамические зависит от устройства пользователя, города, категории клиента, время года, суммы его покупок за год. Скидки и бонусов подтягивается через api сервиса СЛК (Сервил лояльности клиентов) жду хотя бы одного решения
>>3146906 >А почему не триллионы? Ты вообще знаешь как ORM работает? Я-то знаю, ты похоже не знаешь, раз качаешь весь датасет к себе на бэк. Причем тут вообще ОРМ? От него ни холодно ни жарко. >Я даже не знаю почему компании ведутся на такую хуйню. Потому что на конференции сказали, очевидно же. После эпидемии микросервисов об этом даже глупо спрашивать.
>>3146906 Монгошизохуесос. Все что ты тут пытался навалить ПРЕДРАСЧИТЫВАЕТСЯ специальными сервисами. Долбоебу понятно что вычислять все это говно по запросу пользователя тупорылейшее занятие. Так вот после всех этих вычислений остатков и хуятков, у тебя получается таблица с товарами, которые гарантированно можно показать клиентам. И их блядь больше пяти, а показать нужно по пять в каждой категории.
И ты пол треда срешь какой-то хуйней, но никак все не можешь высрать простейший запрос, который возьмет твои джейсончики в монге, сгруппирует и выведет по N записей в каждой группе.
>>3146918 Ты весь тред засрал уже, а реальные задачи для бизнеса так и не решил. Какая-то двачерская маняхуета. Нахуй это бизнесу нужно? Ебать ты Даун конечно. Или ты просто кичишься своим знанием sql? Ну так семь INNER JOIN написать любой студент первого курса сможет. Стажеры Дата аналитики и то лучше запросы пишут.
>ПРЕДРАСЧИТЫВАЕТСЯ специальными сервисами А то мы речь, хуесос. Я ведь не монгошизохуесос, чтобы как тупой еблан всё делать на монге. И не постгресошизохуесос, чтобы как тупой еблан всё делать на постргрес.
>>3146906 >Цены динамические зависит от устройства пользователя, города, категории клиента, время года, суммы его покупок за год. Ну вот, а ты говорил для многоэтажных запросов бизнескейсов нет, а сам описываешь
>>3146925 Ну если у тебя 100 пользователей в твоем онлайн магазине, то в принципе нормально. Иначе при десятках а тем более сотнях тысяч пользователи они будут заходить на сайт и ждать несколько секунд пока твои цены рассчитаются при каждом переходе на новую страницу. тут нужен распределенный key-value чтобы в оперативке все считать — по опыту могу сказать что Ignite отлично справляется с этим. либо какой-нибудь ml решение, ну это тоже не про реляционку. Суть примера в том что ни одна БД в вакууме решает проблему бизнеса. Ни монго ни постгрес ни любая другая. Но для манязадачки с собесов в принципе пойдет.
>>3146939 >распределенный key-value >либо какой-нибудь ml решение >либо Пиздец, прямо блядь две альтернативы. Какое мл решение, чушпан? Ты там совсем ебанулся? С каких пор "ml решение" более быстрое или более распределенное?
Бля с каждым твоим постом все более убеждаюсь что ты просто пациент дурки, который рекламы курсов обчитался.
>>3146946 Плохо когда ты постгресошизохуесос и нихуя в технологиях не разбираешься, да? Иди дальше пиши свое говно по группировке таблицы и выдаче первых пять записей из каждой группы.
>>3146939 >распределенный key-value >чтобы в оперативке все считать Чел, если ты в оперативке считаешь, то твой кейвалью не распределённый, он в твоей оперативке. А распихал по микросервисам ты его потому что "распределенный" звучит круто.
>>3146962 >Чел, если ты в оперативке считаешь, то твой кейвалью не распределённый, он в твоей оперативке Охуеть! Неужели?
>>3146964 >тогда тебе ничего не мешает выгружать датасет в оперативный кэш из обычного SQL Мешает. Данных очень много, а расчёты нужны моментальные. То есть задержка даже не секунды, а миллисекунды. Кэша твоего лэптопа не хватит, поэтому ты распределяешь данные по оперативке десятков или сотен машин. Конечно это не всем нужно. Если ты делаешь магазин для ИП Ашот и Ко, то это на хуй не надо. Можно все сделать на пэхэпэ и постгрес
>>3146974 Слушай, ты хоть кабанчика почитай, что ли. Ты же вообще нихуя не понимаешь, как работает сеть, как хранятся данные, несешь хуету про машин лернинг для сраного кэша, вообще охуеть.
>>3146974 >Мешает. Данных очень много, а расчёты нужны моментальные. Бля, больше десяти лет уже прошло, а джаваскрипт макаки все еще на серьезном ебале думают что мапредьюс это супир быстро и всем дает посасать.
>>3146974 >Данных очень много, а расчёты нужны моментальные Рекомендательные системы обычно лопатят кучу данных и подготавливают ответ оффлайн. Просто делай 30 рекомендаций и фильтруй онлайн по наличию товаров. Выгода в том, что ты можешь намного более сложные штуки подключить чем ты смог бы закодировать в SQL
>>3147275 В ОРМ нет никакой шизы. Это просто ДРУГАЯ задача. Генерация простых запросов за тебя. Кайф же. Даже когда ни ты ни твоя ОРМ не можете написать рекурсивный запрос и тупо выкачиваете все данные на бек - это не шиза, это просто криворукость и лень. А вот когда криворукость и лень преподносятся как ПРАВИЛЬНЫЙ способ - вот это шиза.
То же самое и с технологиями. Если эта замечательная технология делает лучше/быстрее просто вот так. То офк надо брать. Только вот законы физики не наебешь, и в 99% случаев в комплекте идут ебейшие недостатки. Типа закупки нескольких терабайт ecc оперативы для твоего охуенного "RAM кластера", который мапредьюс делает.
Я вот лично ничего против монги не имею, но каждый раз как прибегает монгохуесос и заявляет что монга что-то делает лучше. Он не может с её помощью решить ни одной прикладной задачи. Бегает по треду, орет и постит смешные картинки. При том то на SQL все это делается любым интерном за пять минут.
>>3147154 Плохо когда ты постгресошизохуесос и нихуя в технологиях не разбираешься, да? Это не мапредьюс, а кейвелью, поэтому да, это супир быстро и всем дает посасать.
Как будет работать машинное обучения в кейсе с расчетом цены говна под юзера? Бэк собирает вектор данных о юзере, тянет коэффициенты актуальной модели из базы и множит на вектор, получая цену/коэф цены? Интересно стало
Посоветуйте курсы хорошие. Биг дата, разработчик БД или дата архитектор. Бюджет на обучение выделен, на то что я хотел пойти либо ушли из России либо закрылись.
Во первых: это вообще незаконно. 426 ГК РФ. Но это права потребителей, кого в этой стране вообще права гречневых ебут.
А вот во вторых: если тебя и не нахлобучат по 426, то тебе по этим ценам бух отчетность писать и НДС платить. Разная цена = разный НДС. На один и тот же товар с одной и той же закупочной. А это уже уклонение от налогов со всеми вытекающими. Вот тут-то тебя выебут без смазки, и крыша никакая не поможет.
>>3147471 >Во первых: это вообще незаконно. В перекрёсток зайди в центре Москвы и где-нибудь на окраине в Твери — цены разные. И даже в одном магазине цена для некоторых товаров разная для анонимного покупателя и идентифицированого, который карту лояльности прокатывает. Тоже самое с маркетплейсами. Много раз было когда у меня цена одна, а у друга-брата-свата в этот же момент времени, но в другом регионе немножко другая. Если у тебя подписка есть, цена третья. А если Яндекс Pay каким-нибудь оплатишь вообще другая цена. ГК не нарушается, не переживай. Так как цена реально будет одна и та же абсолютно для всех. Это просто акция для жителей конкретного региона. Или персональные скидки для всех анонов, кроме тебя.
>то тебе по этим ценам бух отчетность писать и НДС платить Это не проблема в век информационных технологий. Ставишь задачу айтишникам и они делают любым интерном за пять минут.
>>3147546 >Или персональные скидки для всех анонов, кроме тебя. Сказочный долбоеб. Будешь в налоговой объяснять почему у тебя с партии товара недоплата НДС идет. Хотя... до этого никогда не дойдет, потому что еще на этапе идеи главбух тебе леща въебет, сидеть-то ей а не тебе, лол.
Ты бы знал какая ебля оформлять бонусную программу по документам. Там год юридической подготовки минимум уйдет. А всякие "платиновые" статусы на самом деле по документам нихуя не статусы, а какие-нибудь "услуги".
>>3147571 Чел ты похоже тупой даун который живёт в каком-то манямирке и с реальным миром не взаимодействуют Я тебе реальный примеры привёл. В Перекрёсток зайди. Там на ценнике две цены. Одна для всех, другая только для тех у кого есть карта лояльности. НДС тебе сложно платить? А кого это ебёт?
>>3147574 Мудила гороховый, ценник это публичная оферта. А бонусная карта это следствие оформления ДОГОВОРА.
Цена на ценнике только одна, это должно быть самое крупное число. Это публичная оферта, по этой цене тебе обязаны продать товар по закону. Второе/третье/перечеркнутое число это не цена, а просто рекламная цифра, никакого юридического смысла она не несет.
А вот снижение основной цены и сумма за которую тебе на самом деле продадут товар определяется заключенным тобой ранее договором, при подписании которого тебе и выдали "скидочную карту", статус которой тоже должен быть прописан в договоре.
>>3147650 >ценник это публичная оферта >Второе/третье/перечеркнутое число это не цена, а просто рекламная цифра, никакого юридического смысла она не несет. А кто-то спорит разве? Всё именно так. И я так написал. Ты жопой что ли читал?
Вот смотри один и тот же товар в двух разных регионах. Ценник в 1279₽ , он же публичная оферта, одинаковые для всех. Никакого ущемление прав какой-либо группы лиц нет. Все согласно закону. А далее просто рекламные цифры, которые юридического смысла не несут, но тем не менее именно по этим рекламным цифрам покупатель приобретёт товар. И я говорю как раз вот про динамическое ценообразование этих рекламных циферок.
>>3147571 >Ты бы знал какая ебля оформлять бонусную программу по документам. Там год юридической подготовки минимум уйдет. Ты даун поэтому у тебя год уйдёт. Берём любую продуктовый сеть, где каждый божий день есть скидка на некоторые товары для всех, на другие товары для владельцев карт лояльности, скидки на промо товары, скидки на товары с почти истекшим сроком годности, скидки за баллы, за большую сумму покупки, за минет твоей мамки. И все это меняется ежедневно, а не раз в несколько лет, пока ты тормознутый даун будешь юридическую подготовку делать.
>>3147747 >Берём любую продуктовый сеть, где каждый божий день есть скидка И эти скидки вместе с оформлением ООО в комплекте идут?
Я когда в не самом крупном ритейлере работал, там только 1С макак было тридцать штук. Это только тех кто инструменты для бухгалтерии писал. Самих бухгалтеров я вообще хуй знает сколько было - отдельный офис трехэтажный.
Там был АРХИВ нахуй с архивариусом, потому что квартальная отчетность это пятьдесят КОРОБОК с мукулатурой, ебучий трехметровый стеллаж. И храниться все это говно несколько лет должно, чтобы если че можно было за любой косяк нахлобучить.
Меняется у него блядь ежедневно. Само ебать меняется. Ну ты и выдал, долбоеб.
>>3147699 >по этим рекламным цифрам покупатель приобретёт товар Если заключал договор. ДОГОВОР, слепой ты долбоеб. И именно в этом договоре четко должно быть описано по каким правилам будет меняться цена.
Нельзя блядь в договоре написать: ну кароч наша нейросеть будет на рандоме ценник хуярить, окда? Там указываются конкретные числа: при покупке на сумму от... каждый потраченный рубль соответствует скидке в сумме... и все это должно быть отражено в отчетности, буквально с указанием дат предыдущих покупок, на основе которых сформирована скидка. С отдельной еблей в очко если происходит переход на следующий год.
А самое главное что это все только при СНИЖЕНИИ цены. Не дай аллах тебе цену хоть на рубль повысить. За такие фокусы сразу пизда. То есть речь идет не о "расчете цен", а только о "формировании скидки".
А при расчете исходной цены нельзя, например, использовать данные конкурентов. За такое тебя нахлобучит уже ФАС. И им похуй будет нейросеть там тебе цену формировала или мясной долбоеб. Можешь загуглить "картельный сговор роботов". Несколько лет назад крупных ритейлеров ебнУли и поимели с них немножко денежек за такую хуйню. И на все отмазки типа "ой ну знаете это жи все кампудахтер вычисляет, автоматически" было строго похуй.
>>3148157 Как можно быть таким тупым? Этот тред про IT. А конкретно про базы данных и про данные в них. И как один из примеров как можно использовать эти данные для динамического ценообразования. Какой на хуй договор? Какой на хуй ГК? Ты ёбнулся что ли? Ну я бы тебе конкретный пример привёл на Яндекс маркете, что разные покупатели видят разную цену на один и тот же товар и соответственно купят его по разным ценам. Хули ты тут тред засираешь? Иди засуди Яндекс маркет перекрёсток ozon и прочие крупные ретейлы. Потом засудили авиакомпании отели такси. РЖД конечно не забудь. Ты что даун что ли запугиваешь двачеров фасом, лол! Или хватит пиздеть и просто иди на хуй.
>>3148157 >А при расчете исходной цены нельзя, например, использовать данные конкурентов. За такое тебя нахлобучит уже ФАС. ЛОЛ! Мальчик похоже насмотрелся голливудских фильмов про IT. Практически во всех компаниях что я работал есть целая команда которая занимается парсингом сайтов конкурентов и всех прочих что может принести пользу. И скажу даже по секрету, все с удовольствием качали слитые базы Яндекс доставки и прочих чтобы использовать для анализа и обучения своих моделей.
>Можешь загуглить "картельный сговор роботов". Несколько лет назад крупных ритейлеров ебнУли и поимели с них немножко денежек за такую хуйню. Один случай из 1000. Чё там ФАС сделает? >Доказать сговор удалось благодаря анализу настроек аукционных роботов – у обеих компаний они были практически идентичны. Роботы делали все, чтобы завершить торги в первую же секунду со снижением цены в 0,5% от максимальной (начальной). Обеим оптовым компаниям грозили штрафы по 35 тысяч на руководителей организаций и порядка 330 тысяч рублей на каждое юрлицо. Ахаха, как страшно. Да и похуй. Велью от инсайтов полученных из этих данных гораздо больше на несколько порядков.
>>3148229 >Hoff >наши категорийные менеджеры предпочли верифицировать вручную, так как экспертная оценка в этом случае была крайне важна Там вообще МЛ используется для "поиска аналогов", и то бля все в ручную потом обрабатывается. Никаких цен Мл не формирует. Тем более индивидуальных.
>Азбука вкуса >Система разработана международной компанией GoalProfit >Sorry, this page doesn't exist. Сайт системы редиректит на 404. Наверное что-то случилось. ГООООООЛ. Опять же, даже если сайт лежит "временно/случайно" речи об индивидуальных ценах нет. Как и следов использования МЛ.
>Хуяндекс.Хачси >Мы решили позаимствовать у машинного обучения метод ближайших соседей для задачи регрессии Это литературно единственное применение МЛ в их ценообразовании. Буквально "рядом лежало". Это блядь уже комедия какая-то - эти долбоебы написали P.S что настоящее МЛ у них используется... в другом месте, хули ноете.
Последняя статья вообще про муррику. И опять непонятно причем там вообще МЛ. Ну придумали хитрожопые барыги менять цену в зависимости от расстояния мобилы до магаза, ну написали скрипт. Нахуй тут "лернинг" уебался. Разве что обучение клиентов отключать отслеживание в мобиле.
Короче ты сам себе в штаны насрал. Никто не использует МЛ для формирования цен. И уж подавно никто не использует МЛ для формирования индивидуальных цен. Динамическое ценообразование офк есть, этого никто и не отрицал, только это процесс сложный и ограниченный определенными правилами, МЛ в нем нахуй не нужен. Вот сопоставить товары по фото это пожалуйста, маршрут "угадать" вместо честного просчета тоже да. А цены слишком точная и важная хуйня, чтобы её генератору шума доверять.
Вообще по откровенном попыткам нагнать хайп в этих статьях можно сделать довольно точный вывод о том кто этот кал потребляет. ГОВНОЕД, нахуя ты эту поебень читаешь? Там пидарасы уже даже не стесняются - тупо лепят тег "машинное обучение", а ты жрешь эту хуйню, еще и сюда тащишь. Фу блядь, фу нахуй.
>>3148249 Ты какую-то хуйню загуглил. Какие нахуй аукционы, ебанько? Вот о чем речь была https://www.vedomosti.ru/business/articles/2017/09/07/732731-robotov-sgovore >Управление Федеральной антимонопольной службы (ФАС) по борьбе с картелями в середине августа провело встречу с вендорами и ритейлерами электроники. Цель – обсудить программы для мониторинга и сравнения цен в интернете, так называемый парсинг. >служба установила, что некоторые торговцы и поставщики используют роботов, чтобы определять цены товара на полке или контролировать розничные цен на продукцию конкретного бренда И этим "конкретным брендом" был Альберт Эйнштейн LG >Участники рынка с опасениями ФАС не согласны. Еще бы они блядь были согласны. Но, спойлер, их согласие никого не ебало. Им въебали несколько лямов штрафа каждому.
И у нас руководство всех программистов собрало и стало решать как бы так наебать, чтобы продолжать парсить. Думали гадали, в итоге только один вариант рабочий - парсить должна сторонняя компания, а ритейлеры у неё будут покупать "просто цены", хуй знает чьи. Офк смысл от такого парсинга сильно теряется. Но когда любой стукачек может выставить контору на несколько лямов штрафа, приходится хавать.
>Чё там ФАС сделает? А будешь выебываться - изымут сервера на "проверку". Ботов искать зловредных. Ты думаешь нахуя закон о возвращении данных в родную говень был принят? С налоговой веселее. Пишут что недоплачено налогов на лям из трехсот, и похуй что вы и три ляма готовы прям щас отдать, только чтобы отъебались. В офис прибывает НОМО и усердно ищет пропавший лям.
>>3148258 >Во первых: это вообще незаконно. 426 ГК РФ >Динамическое ценообразование офк есть, этого никто и не отрицал >Внимание! Я не обосрался! Повторяю! Не обосрался
> Никаких цен Мл не формирует > сайт не открывается > Это блядь уже комедия какая-то > статья вообще про муррику ЛОЛ! Что за манявры пошли? Мы разве обсуждали как у кого-то и на чем цены формируются? Похуй что они там используют. Хоть МЛ, хоть сприпты на фортране. Вопрос был про динамическое образование цен. Что одному пользователю показывает одну цену, а другому пользователю показывает другую цену. Что днём цена одна, ночью другая. Что на iPhone одна цена а на андроиде другая. На что ты ответил, что не существует и не законно, а потом неожиданно переобулся.
>>3148265 >>служба установила, Ну я установил что ты пиздабол который обдристался на дваче при всех и что дальше? >Им въебали несколько лямов штрафа каждому. А чего не триллиардов? Пизди побольше для важности
>Думали гадали, в итоге только один вариант рабочий Ты при этом тоже всем рассказывал про договоры оферты и запугивал фас? Или ты только такое пиздишь, пытаясь показать что тут самый важный?
>А будешь выебываться - изымут сервера на "проверку". >С налоговой веселее. >В офис прибывает НОМО В какой офис? Десятки даже сотни офисов по всей России? Как ты вообще представляешь чтобы в ВТБ или МТС или перекрёсток прибыла налоговая с омоном и начали все изывать? Какие серваки? Там целые датацентры. Вот прям весь датацентр увезут и допустим порушат все сотовую связь в регионе?
Или ты про малый средний бизнес? Ну так вас всё равно будут кошмарить. Неважно есть у вас динамические цены или нет. Есть у нас картельные сговоры или нет.
>>3147412 >Посоветуйте курсы хорошие. Биг дата, разработчик БД или дата архитектор. Бюджет на обучение выделен, на то что я хотел пойти либо ушли из России либо закрылись. Аноны, по курсам подскажите?
Только начинаю разбираться с SQL и никак не могу разобраться кое с чем при написании триггера в Postgresql. Если упростить, у меня есть две таблицы: в первой числовое значение и внешний ключ на вторую таблицу, во второй также числовое значение. Я хочу чтобы при каждом добавлении записи в первую таблицу, он изменял запись второй таблицы на которую ссылается созданная запись, так что к числовому значению записи из второй таблицы будет прибавляться числовое значение из созданной записи в первой таблице.
CREATE TRIGGER sum_tables AFTER INSERT ON table_1 FOR EACH ROW BEGIN UPDATE table_2 SET value2 = value2 + new.value1 WHERE id = table_2_id; END;
Выдает ошибку и т.к. я до конца не понимаю как правильно обращаться к значениям в других таблицах, думаю проблема именно в WHERE. Но как правильно написать все равно не понимаю пока, так что прошу помощи...
>>3148973 >Да конкретной ошибки то и нет А вот эта красная хуйня чисто по приколу висит? Написано же: BEGIN в триггере нельзя использовать. Откуда ты его взял вообще?
https://www.postgresql.org/docs/current/sql-createtrigger.html >The trigger will be associated with the specified table, view, or foreign table and will execute the specified function function_name when certain operations are performed on that table.
1) Называй таблицы ключи и процедуры так, чтобы по названию можно было понять что куда и откуда. 2) Если указываешь тип SERIAL, то и работай с ним как с SERIAL. 3) Триггеры в целом так себе идея. Гораздо лучше будет если ты выполнишь сам в транзакции два запроса - на инсерт и на апдейт.
>>3148258 >Никто не использует МЛ для формирования цен. Крупные ретейлы, маткетплейсы, и даже обсосы используют. Я работал в нескольких крупных компаниях, в которых каждый россиянин хотя бы раз в жизни что-то купил. Конкретно я это не делал, мои задачи были перекладывать данные из одного места в другое, но ребята пилили модели. Практически в любом месте где есть много точек и массовые продажи нужно решить три задачи: по чём продавать, сколько остатков держать на складе, сколько сотрудников выводить на точку. Если у тебя есть история продаж за десятки лет, то на все эти вопросы отлично отвечают ИИ.
>>3149137 >то на все эти вопросы отлично отвечают ИИ Бля, и что же ИИ отвечают на эти вопросы? Отвечают: ебанько, у тебя есть закупочная, себестоимость и ррц, ты че генерировать собрался? Охуеваю с долбоебов с магическим мышлением.
>>3149159 Присылай резюме. У нас как раз ML инженера ищут еще одного. Зарплата для сеньора от 400к + годовая премия 20% от годовых доходов. Я за это бонус получу, а ты узнаешь как ML работает — оба в плюсе.
>>3149170 >Зарплата для сеньора от 400к + годовая премия 20% от годовых доходов Баляяя, эти фантазии потребителя курсов. А еще полцарства и дочь CEO в жены.
Сорян братишка, но твоя выдуманная конторка мне не по размеру. Я занимаюсь реальным машин лернингом - делаю таргетированную рекламу для яндекса. Если тебя неделями после одного единственного поиска заебывала реклама хуйни, котрую ты давно купил, то знай - это я. Мы предиктивно-адаптивно машин лерним нейросети ИИ, чтобы улучшить опыт наших клиентов, получая премию 50% с налерненых за год доходов.
>>3149321 >сливаешь деньги рекламодателей в пизду Ты че, пес. Нейросеть не ошибается. Надежная вещь, вы определенно можете ей доверить свои деньги но лучше чужие. Мы, машин лернеры, не обманываем друг друга.
>форсировать Теперь это тред дружной форсированной нейросемьи.
Добрый день, мужчины. Прошу не обоссывать, а помочь с моей всратой просьбой:
В компании есть 3 сегмента клиентов (сегмент_1, сегмент_2, сегмент_3), при этом клиенты бывают действующими и бывшими, клиенты также имеют разное количество подключенных услуг и находятся в разных городах. Вся информация о клиентах хранится в таблице clients. Структура таблицы выглядит так: (приложил картинкой)
Необходимо выполнить следующие запросы: Запрос №1. Необходимо выбрать всех действующих клиентов сегмента_1 с количеством продуктов больше 2 и находящихся в регионах 002 или 003 или 007.
Запрос №2. Необходимо написать запрос, позволяющий понять распределение кол-ва клиентов в разрезе сегментов, признака flag_client и региона. Используйте агрегирующие функции
Запрос №3. В предыдущий запрос необходимо добавить значение по среднему количеству услуг на одного клиента. Если у клиента нет услуг (cnt_services = 0), тогда необходимо подставить среднее значение по данному региону и сегменту
>>3150548 >Необходимо выбрать всех действующих клиентов сегмента_1 с количеством продуктов больше 2 и находящихся в регионах 002 или 003 или 007. Что-то типа select inn from clients where flag_client = 1 and id_city in (001, 002, 007) and cnt_services > 2
помогите с elasticsearch. храню в индексе ембединги от ады-2. Всего около 300к документов в одном шарде. Пробую дефолтную квери кнн и еластик тума в таймаут улетает. Что посоветуете сделать - серверу больше мощностей дать или квантизировать эмединги?
>>3151531 По большей части там советы "а может поменьше сделаешь вектора?) Оптимизируй, чтобы не было индексации и серча одновременно". В общем проблему я в итоге решил обычной квантизацией, которую можно прям в индексе задать. Пока что не заметил проблем с результатами. Буду дальше тестить. Спасибо за наводки!
>>3151218 >elasticsearch >Всего около 300к документов Забей. Эластик на жабе написан и тормозит уже на паре тысяч документов где латенси 99% плавает в 500-700 мс. Просто провальный проект как и кафка. Ищи альтернативы на нормальных языках программирования
>>3152590 >Ищи альтернативы на нормальных языках программирования так их нет. есть какое-то дрочение, типа расширение для postgres, но мутное и малопопулярное.
>>3153248 Да это какой-то шиз. Забей на него. Я сам не фанат джавы, но только дурак будет отрицать ее производительность и масштабируемость, что важно для систем обработки больших данных. Поэтому и Elasticsearch и Kafka и Hadoop и Cassandra и десятки других инструментов для обработки больших данных написаны на Java
>>3153630 > что важно для систем обработки больших данных Как бы не было смешно, в таких системах производительность больше зависит от стратегий шедулера, а масштабируемость от архитектуры. >>Hadoop >Clickhouse Скорее YTsaurus мимо
>>3159111 Я бы сделал примерно так 1. Сортируешь, добавляешь фиктивную строку с нулём в начало. 2. Смотришь число в прошлой записи (LAG) 3. Убираешь все записи в который LAG отличается от текущей записи более чем на 1. Получаешь отрезки между которыми пустоты. Размножаешь до нескольких записей как хочешь.
>>3159293 Тебя видимо тоже сбило что в моем примере числа идут подряд. Это не точно. Числа это айдишники и мне нужны те, которые есть в запросе, но нет в таблице. Пока вытаскиваю список тех что есть обычным запросом и потом уже на стороне скрипта сравниваю со списком из запроса и нахожу отсутсвующие
Всем здравствуйте. Господа кто нибудь использовал в проектах SQLite ? Работал с ним только для тестов и обучения. Нравится его легковесность. Можно ли с ним развернуть реальный CRUD проект и стоит ли вообще?
>>3163709 SQLite охуенная и даже безальтернативная штучка, когда тебе нужен SQL в каком-нибудь неожиданном месте типа БД приложения . Но для крудов не предназначена, для них лучше даже говнище MySQL, которое никогда бы не взлетело без говнища PHP, которое никогда бы не взлетело без говнища виртуальных LAMP хостингов.
Господа, скиньте мем где чел довольный к злобу Бартунову подходит и говорит что-то типа "Ебать, Лиза Су, когда новые райзеры?". Не могу никак найти его
>>3164096 >в каком-нибудь неожиданном месте типа БД приложения Ебал её рука. SQLite это не отдельный сервер с базой, это просто либа для твоего языка, а "база" это просто файлы на диске.
Соответственно самое выгодное использование SQLite - это когда у тебя всего ОДИН клиент. Где такое? Да в любом приложении, которое использует один человек. Мобила, пекарня, чайник. Поэтому же и используют её для unit тестов - юнит тест по определению должен в изоляции проводиться.
А еще это католическое ПО, которое пишется по "Уставу святого Бенедикта". Поэтому в некоторых странах тебе за него башку отрежут.
TLDR; SQLite используется там где нет КОНКУРЕНЦИИ между пользователями базы. Там где нет возможности/желания поднимать и конфигурировать СЕРВЕР с базой. Если ты богобоязненный КАТОЛИК.
>>3164405 У меня сперва отдельный слой это хеш (слово: айди слова). Айди слов я кодирую по принципу UTF-8. но конечно эти айди вылазят за пределы стандарта юникода. Ну то есть я в принципе просто кодирую массивы чисел по UTF-8. Чтобы это парсить для фуллтекста, нужно на сях мускул немножко закастомить.
Ой я очень прошу прощения за своё существование, я уже в третий тред вопрос этот пишу. Извините.
Дело в том, что через джва месяца с 21 июля закончатся экзамены в шараге у меня, и я пойду в мухосранскую вебстудию на стажировку фуллкакера ларавел вью.
Подскажите, пожалуйста, как sql выучить за ровно джва месяца от корки до корки?
Только не говорите всякое типа хи-хи-хи мы отправим тебя стажироваться в Задний Новгород или что у тебя не получится.
Просто скажите как джва месяца учить си ку эль? Реально надо на сайте sql exercises прошивать джве тысячи раз упражнения? Я ж не успею джве тысячи раз за джва месяца.
Сколько из шапки материалов я успею прочесть за джва месяца.
Очень прошу извинить за такие глупые вопросы, но для меня это вопрос жизни и смерти. Поймите, пожалуйста, меня. А если не поняли, то поймите.
>>3164918 Да знаем мы таких хуесосв. Вместо того чтобы завалить ебало, читать литературу и решать задачи, ты доебываешь всех дебильными вопросами, лишь бы нихуя не делать.
Чтобы выучить sql за ДЖВА МЕСЯЦА надо поменьше пиздеть и делать озабоченное ебало. А побольше РАБОТАТЬ, ПАХАТЬ СУКА.
>>3164918 Перестань искать ответы на такие вопросы. Открываешь браузер заходишь на Metanit или w3school, изучаешь там основы SQL. Потом в любом онлайн портале типа sql-ex ru порешай штук 100 задач. Готово, глубже уже на проекте изучишь.
>>3163709 >Можно ли с ним развернуть реальный CRUD проект Конечно >стоит ли вообще? Зависит. Если ты в компании - лучше делать на стандартных технологиях компании. Если для себя - конечно.
>>3164918 >до корки? то есть в том числе фунции процедуры индексы оптимизация блокировки изоляции управления ошибками ну и все такое или просто селекты уметь хорошо писать?
>>3170286 >просто селекты уметь хорошо писать Лол. Как раз прочитать про блокировки и индексы много ума не надо. А вот СЕЛЕКТЫ ПИСАТЬ ХОРОШО. В этом-то самый цимес. Ты попробуй хотя бы ЧИТАТЬ СЕЛЕКТЫ научись.
>>3170286 Ты не корчи рожу и не брезгуй, просто хорошо писать запросы ага :))
За разработкой много раз переписывал запросы, потому что им нихрена не видно из своей тестовой среды, а у меня есть возможность запускать запрос прямо на проде/продлайке и узнать его истинную скорость исполнения.
Обычно все запросы проходят две-три итерации переписывания, потому что сначала его надо просто сделать и закрыть задачу, а потом уже сделать другую задачу по его ускорению кек
>>3170728 Очевидно, добавляет индексы. Планы надо всегда смотреть на живых данных. Самая веселуха начинается, когда просто добавить индекс недостаточно и надо разбивать запрос на два, внутренний и внешний. Во внутреннем делаем пейджинг и сортировку, во внешнем подтягиваем всякое говно, которое надо для показать иконку в гриде. Приходится собирать запрос из кусков внутри хранимки, получаются эпические стены текста на пять экранов.
>>3170956 Хранимки - это охуенная тема. В них можно собирать большие запросы. На них можно повесить права. Их можно тюнить независимо от кода и на живой базе, актуально когда сервак стоит хуй знает где и показывает слайдшоу через рдп. Никто не говорит писать бизнес логику в базе, но использовать хранимки как интерфейс к базе - это охуенно.
>>3170374 >>3170441 хуясе у вас жопа зашорелась любой разработчик отсосет у аналитика данных, которые реально умеют писать хорошие и сложные селекты используя все возможности языка а разрабы иногда такую тупую хуйню пишут что диву даешься за что им большие зарплаты платят
>>3171065 >Надо учиться писать селекты, это не просто >хуясе у вас жопа зашорелась >любой разработчик отсосет у аналитика данных Ох уж эти проекции про хуи и отсосы.
Поправил твой шизоидный высер. Не благодари. любой разработчик отсосет у любого аналитика данных, которые реально умеют писать хорошие и сложные селекты используя все возможности языка
>>3171088 а за что благодарить то? ну да ты прав про любого. Но любому и не надо. Поэтому аналитики данных, которые как раз крутят вертят данными оч хорошо знают как правильно писать запросы А разрабам не особо надо. моя проекция как раз в этом, что нахуй ему до корки хубрить sql, все равно не пригодится
>>3171346 это случайно не ты тут весь тред хуесосишь мускуль монгу и прочее не постгресное говно, а когда обосрался сразу принес свою желтушную справку от них?
правильно называется вот так: пикрил а если ты нашел какую-то хуету, которую никто не использует, то используй ее про в своей параше и не позорся
давай еще раз объясню что он имел ввиду: часто запросы пишут гигантскими джоинами и набором полей. Прием оптимизации заключается в том, чтобы выбрать маленький объем данных ВНУТРЕННИМ запросом, что-нибудь отфильтровать и отсортировать, а потом доджоинить ВНЕШНИМ запросом остальные поля ( в том числе это может оказаться все та же таблица)
>>3171364 >ВНУТРЕННИМ запросом >давай еще раз объясню что он имел ввиду Хватит семенить. Это и называется "подзапрос". Сorrelated при этом подзапрос или нет вообще похуй, это определят только один раз этот подзапрос будет выполняться или несколько. CTE это тоже "подзапросы". Терминология такая. Простая. А ты её не знаешь но лезешь с умным видом советы давать.
>>3171431 Угомонись, душнила. Анон все правильно написал. Когда говорят внутренний/внешний запрос, все прекрасно понимают, о чем речь. Твою хуйню про correlated subqueries не поймет никто.
Прошел курсы по пайтону и статистике, вкатываюсь аналитику данных. Начал курс по SQL выбрал почти рандомно https://www.coursera.org/learn/sql-for-data-science/home/info Вот там деваха сказала что будет преподавать синтаксис SQLite - я пострел что в принципе востребовано и к тому же на моей федора 40 уже установлен. Так что решил - ладно буду изучать лайт, потом на пост гре пересяду. Вопрос: у меня траблы с работой в терминале. DB Browser for SQLite видит базы данных и их структуру, но команда sqlite3 .databases ничего не отображает. Если открыть базу данных и CREATE TABLE то таблица создается. .scheme отображает изменения. DB Browser for SQLite так же отображает. Однако если в терминале INSERT INTO, то выйдет ошибка что такой таблицы в базе нет.
>>3175432 Чел. Это конечно неприятно слышать. Но. Нихуя хорошего из твоей затеи не выйдет. Это сразу видно человеку с опытом. С первого взгляда. И по тому о чем спрашивают, и по тому как спрашивают. Тебя либо развели/наебали, либо ты сам себя наебал.
Твоя "проблема" это на самом деле не "проблема" - это то как выглядит твоя будущая работа. Пердолинг это как дышать. Или моргать. Этому нигде не учат, но это часть твоей работы. Если ты это не умеешь, то тебе будет плохо всегда. Потому что не работать будет всегда. Что-то всегда будет не так.
Теперь по вопросу. 1) Почему ты спрашиваешь здесь, а не у своей девахи? Какой бы ни был ответ - это повод задуматься нахуй тогда вообще нужен этот курс.
2) Ты даже не можешь сформулировать что ты вообще изучаешь. "буду изучать лайт" что это по твоему должно значить? Есть ЯЗЫК SQL, у этого языка есть куча диалектов и стандартов, с разными возможностями. Есть RDMS - DATABASE MANAGEMENT SYSTEM. Это куча различного софта, очень сильно отличающегося и достаточно сложного чтобы на изучение каждой системы потратить годы. CREATE TABLE это конструкция языка, sqlite3 .databases это команда системы. Команда CREATE TABLE для sqlite, mysql и postgres может сильно отличаться. Так ЧТО ТЫ ИЗУЧАТЬ ТО СОБРАЛСЯ? Диалект SQL для sqlite? Как работает сама sqlite? Зачем тебе это нужно?
3) "выйдет ошибка" Текст команды? Текст ошибки? То что тебя нужно об этом спрашивать, говорит о том что нужно учить не SQL, а повышать компьютерную грамотность. Даже моя бабуля знает, что чтобы найти решение проблемы нужно знать конкретное название этой проблемы. Старушка как никак десть лет кампудахтером пользуется - опытный пользователь пк. А ты - нет.
Теперь попробуем подрубить телепатию. Чтобы что-то найти, нужно сначала определиться что ты потерял и где ты это потерял. Где твоя база? Ты когда запускаешь sqlite из питона, ты указываешь путь до файла с базой. Где этот файл? Он там где и должен быть? Как твоя консоль должна узнать какой путь ты указывал в питоне?
Здарова скюэлисты. Я тут решаю всякие задачки. Но что-то неправильно наверное делаю. CREATE TABLE cars (id INTEGER PRIMARY KEY AUTOINCREMENT, make TEXT NOT NULL);
CREATE TABLE suppliers (id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL, phone_number INTEGER NOT NULL);
CREATE TABLE cars_suppliers (id INTEGER PRIMARY KEY AUTOINCREMENT, cars_id INTEGER NOt NULL, suppliers_id INTEGER NOt NULL, FOREIGN KEY (cars_id) REFERENCES cars(id), FOREIGN KEY (suppliers_id) REFERENCES suppliers(id))
Какая книжка по БД самая уважаемая? А то шапка уже давно не обновлялась. На сайте Постгреса посмотрел книжки, но там чет практики мало, а главное ответов на практику нет или я не знаю где они. Или похуй это все и можно дейтов читать?
>>3181621 >Какая книжка по БД самая уважаемая? Самая уважаемая "Database Systems: Design, Implementation, & Management" от Cengage. Они её обновляют каждый год. Сейчас уже 14-ое издание. Там красочные описания, картинки, чё тебе ещё собака надо. 800 страниц мелкого текста. По ней по-моему даже в вузе преподают.
>>3182806 Потому что хочу и могу. А еще потому, что такой одинокий и тупой анимудебил, как ты, вынужден это терпеть, гореть и вытирать слюни с экрана потом. Еще будут вопросы?
Никак не пойму. Oracle SQL. Почему на некоторых articles пишут что, мол, надо переменные декларировать с "@" (собакой), чтобы показать что это переменная. Также, "@" перед переменной типа говорит что это локальная переменная в процедуре/функции и будет недоступна после её выполнения (на текущую сессию), это так?
А разве не любая переменная объявленная в процедуре будет таковой, например?
CREATE PROCEDURE remove_emp (employee_id NUMBER) AS tot_emps NUMBER; BEGIN DELETE FROM employees WHERE employees.employee_id = remove_emp.employee_id; tot_emps := tot_emps - 1; END; /
Так зачем нужна "@" перед переменной? Я знаю что в другом использовании:
select * from tb1@abcd;
--"abcd" - обозначает другую базу, не в текущей с который ты это ранишь (run).
И еще, кажись на других СУБД, говорится про "$" перед переменной. В Oracle SQL, она тоже типа placeholder? Можно пример как она может использоваться?
>>3191884 >Никак не пойму. >Oracle SQL. >Почему на некоторых articles пишут что, мол, надо переменные декларировать с "@" Пушо ты еблан. Где это пишут? Где в документации это написано? Не используется в оракл для объявления переменных "@".
>>3191944 Слепошарый дегенерат, ты вообще читал что постишь? А ответы ты читал? И вообще, насколько нужно быть угашенным, чтобы ТЕКСТ ВОПРОСА НА СТАКЕ БЛЯДЬ объявлять как " на некоторых articles пишут".
И вообще что за фрукт такой, эта функция OciBindbyName, ну т.е. я прочел что она типа нужна когда передаешь параметры какой-то вызванной процедуре/функции >An OCI application could complete the binds for this statement with a single call to OCIBindByName() to bind the :some_value placeholder by name. In this case, the second placeholder inherits the bind information from the first placeholder. Что за OCI application? Зачем мне эта функция? Она мне пригодится вообще?
Если я хочу получить от пользователя input для variable, чтобы потом значение этого variable передать как параметр процедуре, как это сделать?
Вот например:
CREATE OR REPLACE PROCEDURE remove_emp (employee_id IN NUMBER) IS tot_emps NUMBER; employee_id_input_temp NUMBER; BEGIN
SET SERVEROUTPUT ON accept employee_id_input NUMBER prompt "enter employee id to remove: ";
DELETE FROM employees WHERE employees.employee_id = remove_emp.employee_id; tot_emps := tot_emps - 1; END; /
Только не пойму куда функцию DELETE связанную с Data Manipulation Language впихнуть в код. В общем тут, "&" обозначает адрес переменной в памяти, да? Типа так нужно присвоить значение для employee_id_input_temp
В последнее время замечаю хайп на sqlite, вон всякие ларавели теперь дефолтные конфиги к ней подстраивают. Решил поддаться тем более, что лет 7 назад активно использовал. Теперь использую её вместо постгреса на простых и средних проектах и бед не знаю
>>3192186 >да есть article, просто потерял сайт Нет такой статьи, ты просто по английски читать не умеешь.
>а кстати, что то дает "@" перед переменной? И с чтением по русски проблемы. >Не используется в оракл для объявления переменных "@". >>3191935
>text ename, *job; Это язык какой? Причем тут SQL вообще?
>И вообще что за фрукт такой, эта функция OciBindbyName Ты к чему документацию читаешь, чучело? >The Oracle Call Interface (OCI) is an application programming interface (API) that lets you create applications that use the native procedures or function calls of a third-generation language >third-generation language >OCI supports the datatypes, calling conventions, syntax, and semantics of C and C++. Речь блядь об апи НА ДРУГОМ ЯЗЫКЕ, а не на SQL. Ну ты внатуре пенек осиновый. Ты типа гуглишь случайную хуйню в интернете и тащишь сюда?
>Если я хочу получить от пользователя input для variable, чтобы потом значение этого variable передать как параметр процедуре, как это сделать? Сервер SQL баз данных принимает только один инпут: ЗАПРОСЫ НА ЯЗЫКЕ SQL. Отправляешь SQL серверу запрос, который вызывает твою процедуру и не ебешь людям мозги.
>Ты типа гуглишь случайную Да не, я обычно всегда "oracle sql" вставляю в query гугла, а там что выйдет читаю ну типа, если база данных на ОС oracle стоит, а oracle использует pl/sql то я вот подумал что там когда буду создавать процедуру или функцию, это будет relevant типа это можно будет использовать... теперь буду знать, благодарствую
а так что насчет моего вопроса с процедурой тут >>3192186 как там правильно объявить prompt который потом передавать процедуре
и это все в одной процедуре сделать? типа когда jobs'ом заранишь процедуру (ну или вручную), типа он сразу будет спрашивать чтоб пользователь ввел employer id значение? я так понимаю в pl/sql нету понятие как "pointers"? хотя вроде же вон есть "&" знак, вроде используется, видел в разных кодах...
кстати, я вот сколько гуглю, никак не могу найти команду которую можно было бы в строке SQL plus(?) (NEW -> SQL WINDOW) заранить (F8) чтоб получить информацию об определенной таблице (description) команды describe нет встроенной
SELECT * from USER_TAB_COLUMNS where table_name = 'my_table'; возвращает пустые колонки (TABLE_NAME, COLUMN_NAME, DATA_TYPE, DATA_TYPE_MOD, DATA_TYPE_OWNER и.т.д.) А то сейчас приходится вручную в интерфейсе слева, в директории "Tables" искать и открывать нужную таблицу чтоб посмотреть инфу о таблице. если что я начинающий (стажер в банке), поэтому прошу понять и простить
ну в общем я почитал немного и pl/sql это програмка созданная Allround Automations
а есть просто SQL Developer : A free software tool developed by the company Oracle which could be used for working with SQL in Oracle databases. It is an integrated development environment particularly useful for writing and managing SQL / PLSQL codes.
на нем можно создавать процедуры/функции? или pl/sql типа лучше?
>>3192544 Разницы нет никакой, что pl/sql developer,что sql developer. Процедуры/функции все равно в базе хранятся. Можно их также создавать и компилить через SQLPlus в режиме командной строки, это чисто графические удобные интерфейсы. >>3192443 По сабжу, @ видел только в sql скриптах которые запускаются через SQLplus. Он после запуска запрашивает значения для переменных для подмены. Ну и это все используется в процедурном коде. `script.sql` exec var v = @a begin -- Чета делаем end; sqlplus script -- Вызываем из терминала, и он просит ввести значения чтобы подменить переменную @a Могу ошибаться, на Oracle уже год не программировал
>>3192540 >когда я захожу в базу, я делаю это через иконку pl/sql developer А если на иконке будет написано ХУЕСОС И ПИДАРАС, то ты съебешь отсюда в /ga со своей шизофренией?
Подскажите, это все-таки рабочий код? Если я хочу получить от пользователя input для variable, чтобы потом значение этого variable передать как параметр процедуре, как это сделать?
CREATE OR REPLACE PROCEDURE remove_emp (employee_id IN NUMBER) IS tot_emps NUMBER; employee_id_input_temp NUMBER; BEGIN
SET SERVEROUTPUT ON accept employee_id_input NUMBER prompt "enter employee id to remove: ";
DELETE FROM employees WHERE employees.employee_id = remove_emp.employee_id; tot_emps := tot_emps - 1; END; /
Только не пойму куда функцию DELETE связанную с Data Manipulation Language впихнуть в код. В общем тут, "&" обозначает адрес переменной в памяти, да? Типа так нужно присвоить значение для employee_id_input_temp
Есть таблица на ~500млн записей, у которой есть колонка A с типом Array(String). Сам массив может содержать произвольное кол-во значений (не больше нескольких десятков). Есть необходимость делать 2 типа запросов с использованием этой колонки: 1) поиск записей, у которых колонка A содержит конкретное значение (с использованием функции has) 2) поиск записей, у которых колонка A содержит хотя бы одно значение (с использованием функции notEmpty)
Чтобы не совершать фуллскан, стал смотреть в сторону data-skipping-индексов. Наткнулся на гайд от altinity по использованию bloom_filter (https://kb.altinity.com/altinity-kb-queries-and-syntax/skip-indexes/skip-index-bloom_filter-for-array-column/). Индекс хорошо показал себя в первом типе запросов, но не покрывает второй кейс. Решил посмотреть на индекс с типом set(0), протестил - он покрывает оба кейса (в первом он скипает ровно то же кол-во записей, что и bloom_filter). Но обратил внимание, что кол-во засечек у set больше, чем у bloom_filter - почему так?
Нормальная ли вообще практика использовать set-индекс при работе с массивами? И можно ли каким-то образом увидеть, что он хранит: отдельные значения (строки) из массивов или сами массивы (предполагаю, что второе)? Возможно, стоит вообще как-то изменить структуру таблицы? Если где-то подобный кейс разобран - буду очень благодарен, если кинете в меня ссылкой
Читаю вики про уровни изоляции транзакций и вот такой текст: Repeatable read (повторяющееся чтение)
Уровень, при котором читающая транзакция «не видит» изменения данных, которые были ею ранее прочитаны. При этом никакая другая транзакция не может изменять данные, читаемые текущей транзакцией, пока та не окончена.
Как я понял, предложение "Уровень, при котором читающая транзакция «не видит» изменения данных, которые были ею ранее прочитаны. " означает, что сначала читающая транзакция прочитала какие-то данные, потом кто-то изменил их, но т.к. читающая транзакция все еще открыта, то она не видит этих изменений. Но вторая часть текста смущает меня. Как я понял, она говорит следующее: если какая-то транзакция читает какие-то данные, то другая транзакция не имеет права изменять их до тех пор, пока читающая транзакция не закроется. Но это противоречит тому, что я понял в первом предложении. Так как все-таки правильно?
>>3198472 1) Сразу пиши базу и её версию. Делать больше нехуй высматривать это на твоих скриншотах. 2) Сразу пиши свой запрос здесь https://dbfiddle.uk/S9ZOHCkV Так не только легко понять что ты делаешь, но еще и легко что-то ПОКАЗАТЬ уже тебе.
У тебя в запросе используется correlated subquery - подзапрос, который использует данные из наружного запроса. Этот подзапрос выполняется по разу для каждой найденной строки из person_order.
Товарищи инженеры данных, ЕТЛщики, а может даже БИ разработчики, хер с вами, даже вас бы наверное сейчас послушал уровня мидл и выше. Какие у вас карьерные амбиции? Сколько вы сейчас зарабатываете? Сколько хотите зарабатывать? Я простой ДЕ город ДС, зп 250к, были оферы из банков на большую сумму, но я пока не принял. Крч, я щас задумался, что текущее положение дел меня устраивало раньше, но сейчас не особо. Хочу апнуться по зп, хотя бы на х3, по возможности работать на барина из Эмиратов и лутать свою зп в долларах ну или хотя бы в юанях. Есть ли у меня возможность к этому прийти не меняя ИТ область, я даже наверное хадупы и спарки освоить готов, но пиздец как не хочется. Крч, дайте совет, есть ли возможность и если есть, куда хотя бы примерно двигаться, чтобы достичь своих финансовых целей.
>>3198635 Бля, как к вам вкатиться можно, если опыт работы с БД есть, но он ущербный? Я сам всю эту хуету двх етл знаю, но хз как попасть на работу такую.
select a.id, a.col1, a.col2, b.col1, b.col2 from ( select cl.col3, cl.col4 from table clients cl order by cl.date desc)gr1 table 1 a, table 1 b where a.id = b.id and a.col1 = 'some condition' and b.col1 != a.col1 and a.col2 = gr1.col3
каким образом уменьшит нагрузку на процессор? и вообще когда есть подзапрос, как тот же oracle с ним поступает?
он сначала берет все результаты которые возвращает подзапрос, или он сначала подсовывает and a.col2 = gr1.col3
где gr1 относится к подзапросу и ТОЛЬКО ПОТОМ, из тех мелких результатов уже делает: order by cl.date desc
\или же он сначала берет все с таблицы clients, пытается все результаты отсортировать по дате и только потом фильтрует по: and a.col2 = gr1.col3 ?
Можете коротко и с каким нибудь жизненным примером пояснить про optimistic/pessimistic locking? Читал, смотрел юзкейсы но пока не совсем сложилось понимание когда нужно применять и для чего.
>>3200397 Делает CROSS JOIN удваивая таблицу, потом correlated subquery делая по запросу на КАЖДУЮ УДВОЕННУЮ СТРОКУ, потом несет какую-то шизу про цпу. Тебе не похуй? Ты итак уже всю таблицу пару раз в память прочитал, память забил и вселенную нагрел.
>>3198628 Офигенно анон, спасибо! Что это за тулза такая? Чем отличается seq scan от index scan? Есть мб какая-нибудь тулза которая визуально показывает этот процесс или видос?
>>3200450 так обычный inner join также удваивает разве что если select distinct делать? >Делает CROSS JOIN удваивая таблицу, потом correlated subquery а вот это - печалька почему oracle не предусмотрели возможность сначала select в подзапросе отфильтровать ... или стой, а если так буду делать: select a.id, a.col1, a.col2, b.col1, b.col2 from ( select cl.col3, cl.col4 from table clients cl where cl.col3 = a.col2 order by cl.date desc)gr1 table 1 a, table 1 b where a.id = b.id and a.col1 = 'some condition' and b.col1 != a.col1
может oracle тогда сначала посмотрит... ну я понимаю что это сложновато, but hear me out for a sec, что если oracle сначала отфильтрует по условиям: where a.id = b.id and a.col1 = 'some condition' and b.col1 != a.col1
table1, table2
а потом, будет подзапрос отфильтровывать, т.е. посмотрит на результаты с table1, table2 и такой: "аха, ну вот беру первое попавшееся значение в a.col2 из результата с table1, table2, и пытаюсь найти совпадение в clients таблице нашел совпадение, все отличненько, теперь иду дальше, беру следующую строку из результата с table1, table2, и опять ищу по нему совпадение в таблице clients, и уже потом буду как надо слеплю этот результат с результатом с table1, table2"
т.е. ORACLE, вместо того чтобы сначала ВЫГРУЗИТЬ всю таблицу clients (где может быть несколько миллионов строк), и только ПОТОМ по этой выгрузке пытаться находить совпадение с результата с table1, table2 ну - так себе
ну типа в первом случае же он не выгружает всю таблицу, да? когда он по одному берет значения колонки a.col2 с результата с table1, table2 и пытается найти нужно строку в таблице clients? т.е. по сути что если ты как юзер заранил бы вот так: select cl.col3, cl.col4 from clients where cl.col3 = 'literal string'
и так по несколько раз, подставляя литералы и ищя совпадения
а то мне кажется что oracle делает как во втором случае
сначала выгражает всю таблицу, и потом matching:
select cl.col3, cl.col4 (select cl2.col3, cl2.col4 from clients cl2)cl where cl.col3 = 'literal string' и так по нескольк раз, где 'literal string' будет разным.
надеюсь все понятно, по идее если давно знаком с SQL, то должно быть понятненько что я пытаюсь донести
я так понимаю по умолчанию нету logging если у меня обычный доступ например я не вижу DBMS_HPROF package, хотя по поиску: SELECT * FROM all_source where UPPER(TEXT) like UPPER('%hprof%')
он выскакивает, в первом столбце (owner) написано "SYS"
я хотел посмотреть сколько по времени stored procedure занимает runtime'а
>>3200872 Так профилируй у себя, уебище. Нахуй ты сюда срешь своими стенами того как тебе че-то там кажется? Отпрофилируй свой запрос и все. Кретин ебучий.
Как становятся дата инженерами? Приходят из других областей? Если да, то каких? Как им стать, если нет никакого технического бэкграунда, но при этом необходим опыт?
>>3122886 (OP) Ананасы, я простая макака, пишущая простые бекенды, SQL я по сути не знаю, всегда пользовался ORM (TypeORM, Prisma). Где мне максимально быстро и удобно прокачать минимальную базу по базам данных и по SQL чтобы не обсираться на серьёзных собеседованиях?
>>3204788 Существует множество онлайн-курсов и ресурсов, которые помогут Вам освоить базы данных и SQL. Некоторые из них включают Codecademy, Coursera, Udemy, Khan Academy и W3Schools. Кроме того, Вы можете найти множество бесплатных учебных материалов на YouTube и в блогах. Рекомендуется также практиковать навыки SQL на практических примерах, поскольку это поможет Вам лучше понять и запомнить материал.
>>3201189 >Если я хочу получить от пользователя input для variable, чтобы потом значение этого variable передать как параметр процедуре, как это сделать? Для этого тебе вообще не нужно вообще никакие тем переменные и получения адреса, удали employee_id_input_temp := &employee_id_input; и передавай напрямую employee_id_input куда надо
>>3208254 А нахуя тебе ЦЕЛАЯ ТАБЛИЦА? Ну сделай всего одну таблицу, в ней одну jsonb колонку, и в каждой строке храни ВСЕ сущности сразу. Подумаешь был json массив двойной вложенности, а стал тройной. Зато все в одном месте и на таблицах сэкономили. СМЕ-КАЛ-ОЧКА
>>3208530 А все файлы хранить в числе π. Всего-то нужно знать с которого знака твой файл начинается. Теперь вместо файлов на диске только один json со списком отступов.
ПРОБЛЕМА С ПАРОЛЕМ
Аноним06/07/24 Суб 13:04:17№3213257399
>>3215165 У нас так сделано в паре проектов, там целая иерархия из таблиц, почти как с наследованием в ООП. Модель данных специфичная, есть несколько десятков типов сущностей, у каждого типа свои атрибуты. Полёт нормальный, но для вывода списка всех записей для отображения юзеру надо писать трёхэтажный селект с джойнами и юнионами.
>>3215784 >но для вывода списка всех записей для отображения юзеру надо писать трёхэтажный селект с джойнами и юнионами. Джойны, юнионы, груп_конкаты - это я привык всё, да. Просто у меня собственный автоинкрементный айдишник дочерней таблицы по сути и не используется нигде, джойны эти все цепляются по внешнему ключу от родительской таблицы, а юзеру он нахуй не нужен, ему из основной таблицы первичный ключ надо. Вот я и подумал совместить их в одном поле, он всё равно уникальным будет. Ну раз нормально - значит, так и сделаю, спасибо.
>>3215165 А нахуя? Ну кроме "кажется" и "захотелось"? Нахуя делить одну таблицу на две? Какой профит? Так ведь если это "выгодно" можно для каждой колонки по таблице сделать.
>>3215872 Сущность Б также является сущностью А, но обратное неверно. Иметь для каждой сущности А колонки, специфичные для сущности Б - нелогично. Вот исходя из такой логики и придумал это всё. Вряд ли это "выгодно" с точки зрения производительности (хотя джойны по праймари кеям работают достаточно быстро и значительной разницы не будет), но чуть меньше путаницы получается.
>>3216304 Хуятно. Вот щитпостишь ты на сосаче, где все треды - это посты, но не все посты это треды. Значит, что-то отличает тред от регулярного поста, и это не только нулевой родитель. У треда дохуя метадаты - закрыт не закрыт, прикреплён не прикреплён, достигнут ли бамп-лимит, когда был последний бамп, etc. Надо для каждого поста колонки pinned и closed держать? А как проверять данные на апдейтах и инзертах? Ведь если это тред, то все обязательные для треда поля должны быть не пустыми, а если не тред, то все должны быть пустыми. Ебанутые жирные checkи для каждой колонки городить? Или на уровне приложения валидаторы говнокодить будешь?
>>3216318 Мудила, гороховый, мне тебе тут википедию по нормальным формам зачитывать? Ну не знаешь ты нихуя. Ну не читал ты нихуя. Нет у тебя образования по теме. Ну нахуй ты пиздишь тогда? Нахуя ты ебло свое разеваешь?
>>3216339 >Ясно Понятно? Впитал мудрость? Вот так надо вас слепошарых, ленивых долбоебов учить. Википедию блядь ему почитай. Мамка почитает, за тарелочкой борща.
>>3216355 Так я тебе даже конкретный пример привёл, зачем это нужно, мудило. Всё, что ты, чепушило с ОБРАЗОВАНИЕМ, смог родить высрать в ответ -- нууээээыыы пукмням нормальные формы. Иди нахуй, короче, зелень ебаная.
>>3216376 Наебал, запутал, затралел. Ну ты внатуре дебил? Ты че ждешь, что я тебе нахуй тут составлю курс по реляционной теории? Что такое отношения, избыточность, нормальные формы? Первый семестр, второй?
Открой свои залитые стекломоем шары и прочитай хоть что-нибудь из шапки по теме, дегенерат ебучий. Просто охуеть. С каждым годом все более тупорылые дифиченты лезут.
>>3216423 Тупорылый, дырявый кретин. Данные в реляционной базе хранятся в виде отношений колонок к первичному ключу. Поэтому, сука ты проткнутая, база называется РЕЛЯЦИОННОЙ. Колонки относящиеся к первичному ключу 1 к 1 образуют таблицу. Если отношение 1 к n, то это уже другая таблица.
Это можно выразить рядом предикатов, каждый из которых формирует факт о записи в таблице. Если предикаты относятся к записи через конъюнкцию, то эти предикаты относятся к одной таблице фактов. А если через дизъюнкцию, то к другой.
Так вот нормальные формы и формируют правила построения таблиц с непроитиворечивыми фактами. Не может блядь в реляционной модели быть одновременно истинным предикат "это пост" и "это тред". Между ними должна быть диъюнкция "это пост или это тред". И это блядь значит что пост и тред - это разные таблицы, гандон ты использованный.
>>3216447 >ну нада сделоть копипасту две почти одинаковых таблицы и в одну чуть больше полей напихать уминя АБРАЗАВАНЯ яскозал а ты дурак А завтра сосака захочет переделать сосач в реддит и решит, что треды могут идти лесенкой вплоть до энной или бесконечной вложенности. И что теперь, базу мигрировать, все посты тредами делать и таблицы ворочать?
>>3216467 Пчел, если у тебя не реляционные данные - не используй реляционную базу.
Ты просто не умеешь пользоваться инструментом. А когда тебе об этом сказали, вместо того чтобы пойти почитать какого-нибудь дейта, ты порвался и залил весь тред говном.
>>3216476 >ты порвался Эта мощная проекция чмони, изливающегося отборной желчью вот уже второй десяток постов и неспособного ответить на элементарный вопрос, лол. Интересные у тебя аутотренинги. >не используй реляционную базу. А альтернатив условному sqlite и нет особо, щито поделать.
Выдало ошибку The type initializer for 'Npgsql.EntityFrameworkCore.PostgreSQL.Storage.Internal.Mapping.NpgsqlBigIntegerTypeMapping' threw an exception. когда подключал готовую базу данных по этому гайду: https://metanit.com/sharp/efcore/7.3.php (в конце). Все делал по гайду.
>>3217695 Это вопрос скорее к Entity Framework, чем к базам данных, лучше спрашивать в профильном треде про шарп. Вероятно, строка подключения неправильная.
Привет всем. ЕОТ(есть одна таблица postgres), в ней колонка numeric(38)( хз почему, но в ней значения строго ограничены по факту 1-5). Стоит btree индекс на колонке. Когда использую запрос col != 4, и делать explain, то пишет, что перебор идет. Я попробовал заменить col > 4 and col < 4, тут начинаются приколы. Когда запускаю col > 4, то индекс применяется. Когда запускаю col < 4, то перебор. Итого col > 4 and col < 4 перебор. Я не знаю как быть, блин.
>>3222221 Ну так и где explain? Может быть миллион причин почему индекс не используется. Может у тебя col < 4 это почти вся таблица, и если ты селектишь не только индекс, то и нахуй индекс тогда использовать, если все равно всю таблицу читать нужно?
Раз за разом одно и то же. Ебучий черный ящик. Сделай сниппет https://dbfiddle.uk/S9ZOHCkV создай в нем таблицу, заполни и напиши запрос. Только тогда можно будет что-то конкретно сказать и показать. А то ни таблицы, ни запроса, ни эксплейна, нихуя. Что в черном ящике?
Всем привет, пытаюсь понять B-tree индекс, в интернете гуляет два вида дерева. В верхнем мы видим, что в корне 3 ключа и 3 дочерних узла - в каждом узле значения начинаются с ключа. А в нижнем в корне также 3 ключа, но уже 4 дочерних узла - но диапазоны немного другие, + значения корневых ключей не включаются. Никак не могу найти именно разницу, везде описывается либо первый кейс, либо второй. А как на самом деле то блять?
>>3222976 Вопрос скорее не про базы данных, а про структуры данных как таковые. Дочерний узел может не включать ключ из родительского узла, ключи дочернего узла просто должны соответствовать диапазону, т.е., если написано "от 4 до 32", то 4 не обязательно должно присутствовать в узле, узел может начинаться и с 5, и с 6.
>>3222976 >в интернете гуляет два вида дерева Куда они нахуй гуляют? Вдоль по улице? Открываешь ютуб, пишешь b-tree и тебе миллион протыков в прямом эфире все строят и объясняют.
А по поводу количества нод. Ты определение b-tree читал? Это СБАЛАСНИРОВАННОЕ блядь дерево. Как сбалансированное? Да как угодно, так как нам надо блядь. По ситуации епты. В базах надо чтобы деревья было быстро и удобно с диска читать, под это и балансируют. Глубина поменьше, нод побольше. https://habr.com/ru/articles/783012/
>>3222976 С деревьями каша в голове даже у ученых моченых. Помню скопипиздил алгоритм удаления с балансировкой из книги VB algorithms, а там баг был стремный, который только при определенной конфигурации узлов проявлялся. Потом я с ебалом пикрил три дня сидел. Так что ты там осторожнее.
Анонасы, посоветуйте курсы/видео/книги по шардированию в постгресе. Я искал, но находил либо говорунов ртом, которые все 3 часа только пиздели и ничего не делали, либо книги в которых всё так нудно и заумно написанно, что нихера не понятно.
Пытаюсь тут начать работать с докером. Вот есть у меня маленький проект на python+postgres. Я хотел бы подготовить контейнер, при запуске которого сервис сразу же начал бы работать. Но что-то я явно делаю неправильно. Пытаюсь делать как в туториале, но консоль ругается. Вопрос: docker run --name habr-pg-13.3 -p 5432:5432 -e POSTGRES_USER=habrpguser -e POSTGRES_PASSWORD=pgpwd4habr -e POSTGRES_DB=habrdb -d -v "/Users/ivahrusev/src/useful-sql-scripts/running_pg_in_docker/2. Init Database":/docker-entrypoint-initdb.d postgres:13.3
в папке 2. Init Database (Это из туториала. У него явно все прокатило) скрипты на каком языке должны лежать?
В моем случае результат выглядит так: docker: Error response from daemon: error while creating mount source path '/Users/user/Desktop/projects/horses/horsebot/table/init': mkdir /Users: file exists.
Есть два класса Автор - Книга. Как мне в postgresql базе обновить строки где name='Name1' на 'Name2' наиболее простым способом? упрощенный вариант ситауции возникшей на работе; я не знаю мб это можно средствами django на изи ещё как-то сделать
Гопота советовала дропнуть все foreign key constraints и руками UPDATE сделать. Но мне не захотелось ебаться с миграциями джанго туда сюда, и там было на самом деле 5+ таблиц которые зависели от основной.
Как мне сейчас кажется там таблица Автор должна иметь id автоинкремент pk, и другие уже на этот id подписываются не я изначально модели создавал. Тогда бы изи можно было обновить поле в Автор и похуй было бы, правильно же?
>>3250427 > таблица Автор должна иметь id автоинкремент pk, и другие уже на этот id подписываются Да. ID как раз для того и придуманы, чтобы не возникало проблем как у тебя. Правильнее всего будет добавить ID и сразу сгенерировать значения для существующих записей. Хз, как это делается в джанге, но в нативном SQL это делается так: https://stackoverflow.com/questions/2944499/ . Ну и доработать форенкеи в других таблицах. Можно, конечно, и по-тупому выключить констреинты, проапдейтить и опять включить только делать это придётся каждый раз при изменении имени.
При проектировании миграций при разработке архитектуры новых таблиц баз данных, я всегда ставлю индексы на те колонки, которые, на мой взгляд, будут часто использоваться при поиске, например, на email в таблице пользователей.
Также я ставлю индексы на все колонки с _id, которые участвуют в соотношениях, т.к. в reference или связях, один ко многим, допустим.
Допустим, order_id, user_id и т.п, потому что такие колонки всегда участвуют в поиске с джоинами какими-нибудь.
Но несколько дней назад мне в голову сказали, что такой подход не правильный, и нужно всегда смотреть на время выполнения запросов и на их частоту, и брать для индексов колонки только оттуда.
Я понимаю, что и такой подход верный, т.е. если в логах есть, например, колонка с created_at в запросе, который длится 20 секунд, то ее нужно добавить в индекс тоже, но почему нельзя ставить индексы всегда на колонки с _id ?
Вот я создаю таблицу, почему ставить сразу индекс на user_id не верно?
>>3250894 Ты никогда не угадаешь, как планировщик построит запрос, а лишние индексы только тормозят базу. Надо смотреть план запроса на живых данных. Где table scan - туда индекс, где table lookup на одно-два поля - добавляешь эти поля в индекс как include, не напрямую. Снова смотришь план, если не помогло - откатываешь. В особо тяжелых случаях с пейджингом разделяешь запрос на внутренний и внешний.
>>3250894 >нужно всегда смотреть на время выполнения запросов и на их частоту, и брать для индексов колонки только оттуда. Ну так тебе логи и скажут что нужно по колонке с внешним ключем индекс делать.
>если в логах есть, например, колонка с created_at в запросе, который длится 20 секунд, то ее нужно добавить в индекс тоже Железная логика. Добавляешь все поля из селекта в индекс и кайфуешь. Нахуя только тебе сама таблица при таких раскладах, непонятно.
>Вот я создаю таблицу, почему ставить сразу индекс на user_id не верно? Не почему. Ставить индекс верно если он снижает нагрузку на базу, и не верно если повышает. Если речь о нагруженной базе, то у тебя не будет времени собирать статистику - твой запрос забьет доступ к диску и она блядь ляжет вся. Поэтому башкой надо думать заранее.
>>3250936 >Ну так тебе логи и скажут Не роляет, если у тебя много разных инсталляций продукта. Даже если инстанс один, то ты не можешь угадать когда добавить нужный индекс. Каждый индекс - это тормоза на запись
>>3251605 >Не роляет, если у тебя много разных инсталляций продукта. И? База то у тебя на сервере. Или ты имеешь ввиду что у каждой инсталяции своя база? Это настолько редкий случай, что смысла его обсуждать нет. Там и без базы ебли куча.
>Даже если инстанс один, то ты не можешь угадать когда добавить нужный индекс. Получается тогда что все индексы в мире созданы от пизды и на самом деле снижают производительность, потому что "даже угадать нельзя". Ну или ты написал какую-то невероятно тупую хуйню.
>Каждый индекс - это тормоза на запись Ноу щит, шерлок. А запросы без индекса - это тормоза на чтение. И чего? Выводы какие?
>>3251763 Ты просто очередной крудошлеп, который лепит репазитарий в спрэнг фримверке со своими файндБайИмэйлЭндЮзерСтатус, а потом бежит лепить миграцию на бд, чтобы воткнуть два новых индекса. Поэтому таких лепил и попускают на собесах и дрочат вопросами из кабанчика
>>3251833 Что ты там собрался читать? Кабанчик - это тупо обзорный справочник. Бывают базы такие, а бывают другие, ну заебись, дальше что? Всей командой прочитали кабанчика и заменили кафку на кафку.
>>3251803 >Ставить индекс верно если он снижает нагрузку на базу, и не верно если повышает. >кабанчик Ебанарий, ты в кабанчике прочитал что это не так? Или тебя на собесах выдрочили?
Пацаны, нужна ваша помощь в вопросе по оптимизации.
Есть сайт с книгами. Там есть таблица book_chapters c полями: book_id (ID книги) | title (Название главы) | content (Текст главы)
Текст главы (поле content) может быть ОЧЕНЬ ОГРОМНЫМ, вплоть до несколько мегабайт.
Так вот, много где используется запрос SELECT title FROM book_chapters WHERE book_id = XXX только лишь для того, чтобы вывести список глав, оглавление книги, но тексты не нужны.
Скажите, может лучше разделить таблицу на две, где в одной таблице будет список глав: book_title (id, book_id, title) а в другой - текст к этим главам: title_text (title_id, content) ?
Чтобы запрос для получения только оглавления был к отдельной легкой таблице без текста
>>3252687 Хм, хорошо если и так. Просто у меня где то в памяти висит текст какой-то статьи, забыл уже, что то типа "когда ищется в строке с большим размерами, то требуется больше оперативной памяти и больше времени, даже несмотря на то, что я ограничил SELECT легкими полями."
>>3252703 А разве не так работает. Ну типа сделал запрос select title from book_chapters where book_id=1555. Хоть я и ограничил по title, все равно внутри выгрузятся все строки, чтобы оттуда потом извлечь только title.
Например, нашлось 10 глав с текстами общим размером 5 мегабайт. То есть аж 5 мегабайт выгрузилось в память, вместе с названиями глав, и текстами этих глав, но мне нужно только главы, которые занимают в общей сложности ну примерно 500 байт. Эдак память быстро забьется.
>>3252708 Выполнил, все норм. Все же по индексам ищется, какие могут быть проблемы. Но как мне например инсценировать что тысячи человек могут откроют страницу где выведены десятки книг с главами. Я не тестировщик, я не умею
>>3252712 >А разве не так работает. А разве на каждый запрос не вся таблица стразу грузится? Хоть ты и граничил по id, все равно внутри выгрузятся все строки, чтобы оттуда извлечь только твою.
Чел, хуйню не неси. Ты спросил - тебе ответили.
>Но как мне например инсценировать что тысячи человек могут откроют страницу где выведены десятки книг с главами Похуй. Не будет никаких тысяч человек.
>>3252736 >выгрузятся все строки Чел, таблица весит 5.6 гигов на данный момент. Ясное дело, что она не выгружается целиком. Там все явно не так работает.
>>3252738 Да не пизди. Когда тебе нужна одна колонка, то всю строку грузит, а когда тебе нужна одна строка всю таблицу не грузит что-ли? Надо на хабре спросить обязательно.
Короче, я познал дзен двух стульев. Не знаешь, какой стул выбрать - спроси. Если нет утвердительного ответа - значит, можешь выбрать любой, значит, у каждого стула есть плюсы и минусы. А вот если большинство утвердительно говорит - вот этот стул нужен - то этот стул и бери. Иногда и правда бывают такие ситуации, когда нет единого идеального решения - тогда можно выбрать любой стул. Однако, если ты выбрал стул "А", то могут налететь поклонники стула "Б". Но в этом случае ты не один, у тебя будут сторонники стула "А", а это твоя поддержка, твоя личная армия - вот и страви их.
Ладно, я тут загуглил, не надо отделять text и прочие больше поля в отдельную таблицу, они и так отдельно хранятся, даже если в одной таблице, если есть вот такой параметр innodb_file_format=barracuda
В тысячный раз сообщаем : SQL - декларативный язык. Ты никогда не можешь быть уверен в том какой способ обработки выберет сервер. Да и не нужно это тебе.
Да, при некоторых условиях загрузит все пачкой без индекса. Добиться этого непросто, но точно возможно. Иди нахуй, не буду ради тебя это делать.
>>3260937 Бля реально ВСЁ. Можно хоть на луну полететь. Вкатывайся в трейдинг опционами и будешь иметь хоть миллион рублей в неделю, работая по полчаса в день. А айти - это просто наёмная работа. Это не "кнопка бабло", которую нажал и бабло посыпалось. Это не наебизнес. Сверхзарплат здесь не так чтобы много. Если ты хочешь именно сверхзарплату, то вкатывайся в инвестиции, трейдинг, венчурные инвестиции, открывай свою фирму, и будет тебе и ламборгини и всё остальное.
>>3261007 Хоти дальше. Чел, наёмная работа - это продажа времени в обмен на деньги. Не стоит твой час 500к / 5 дней x 2 часа х 4 недели = 12,5к рублей/час. Ты же не Вероника Степанова и не Бейонс. Рассмотри вышеприведенный вариант с опционами/фьючерсами. Там выхлоп прямо пропорционален вложенным средствам. Если ты дохуя вложил, то дохуя можешь и получить. Мало вложил, значит и маленький будет выхлоп. И работай хоть по 5 минут в день.
Аноны, работаю инженером, проверяю поступающие изменения, которые приходят из др.организации в вордовскх доках десятками пикрел. По внешнему виду др.организация выгружает из sql в word и отправляет дальше. Я же перевожу в excel через "Текст по столбцам" и работаю дальше.
Хочу эту тупую работу передать psql да и в целом начать в нем работать, но как загрузить эти вордовские таблицы не знаю, на РАБоте спросить не у кого, c трудом excel понимают.
Уже скачал pgAdmi 4 и докачиваю dbeaver. Буду рад любой инфе.
>>3262434 Готовых тулз не знаю, я бы прогуглил что-то в стиле word table to sql, если не получится, то прогуглил бы как каком-нибудь питоне (там скорее всего есть тулинг) распарсить вордовский док и написал бы на нем скрипт, который будет парсить доки, доставать данные из табличек и писать в бдшку. прогуглил на английском парсинг, по первой ссылке есть что-то похожее на нужное тебе https://stackoverflow.com/questions/58254609/python-docx-parse-a-table-to-panda-dataframe Если у тебя объемы данных небольшие и история с прошлых файлов не нужна, то и манипуляровать данными прямо в питоне удобнее будет, например, в том же пандасе.
>>3262434 Вообще, есть варик подключиться к постгресу прямо из ворда. Есть специальный драйвер для микрософта https://odbc.postgresql.org/ Через него виндовский софт отлично коннектится к постгресу. У меня микрософтовский офис не стоит, но вот пикрелейтед libre office отлично коннектится.
>>3262856 Похоже, не получится это сделать просто, как хотелось. Если я правильно понял, это для готовых таблиц, а у меня куча символов, которые надочерез что-то пропустить, наверное пандас для этого и нужен. В общих чертах понимаю механизм, а реализовать затрудняюсь, с питоном дел не имел.
>>3262955 Крутое применение, но он вытягивает данные с сервера, а я наоборот хочу туда перенести, опять же, если я правильно понял что он делает
походу нужно какой-то язык программирования учить.
>>3264038 >он вытягивает данные с сервера, а я наоборот хочу туда перенести Он выполняет запросы к базе. Шли запросы не SELECT, а INSERT и будет тебе наоборот.
>походу нужно какой-то язык программирования учить Чел, кто ж тебе виноват что ты даже с вордом работать не умеешь. Эта хуйня так-то в школьной программе есть.
Где сайт/серверное приложение должно хранить тяжелые мультимедия-файлы? Всякие иконки можно в блобе хранить, так? А всякие видео, галерею и тд в виртуальной папке или туда же?
>>3266284 В файловой системе. > Где сайт/серверное приложение должно хранить тяжелые мультимедия-файлы? Уж точно не в базе данных. > Всякие иконки можно в блобе хранить, так? Нет.